


Недавно, на Geektimes я опубликовал статью, где привёл немного поверхностной статистики из серии книг «Песнь льда и пламени». Но я не стал углубляться в самую интересную часть, в граф социальных связей, ибо тема заслуживает отдельного внимания. В этой статье я продемонстрирую как теория графов может помочь при анализе подобных данных и приведу реализации алгоритмов, которыми я пользовался.
Всем кому интересно, добро пожаловать под кат.
Из опроса вышеупомянутой статьи, я сделал вывод, что больше трети аудитории Geektimes ознакомлено с книгой фентези романа, а больше половины с сюжетом из сериала. Я надеюсь, аудитории Geektimes и Habrahabr пересекаются и вам возможно будут интересны не только использованные алгоритмы, но и результаты.
Данные
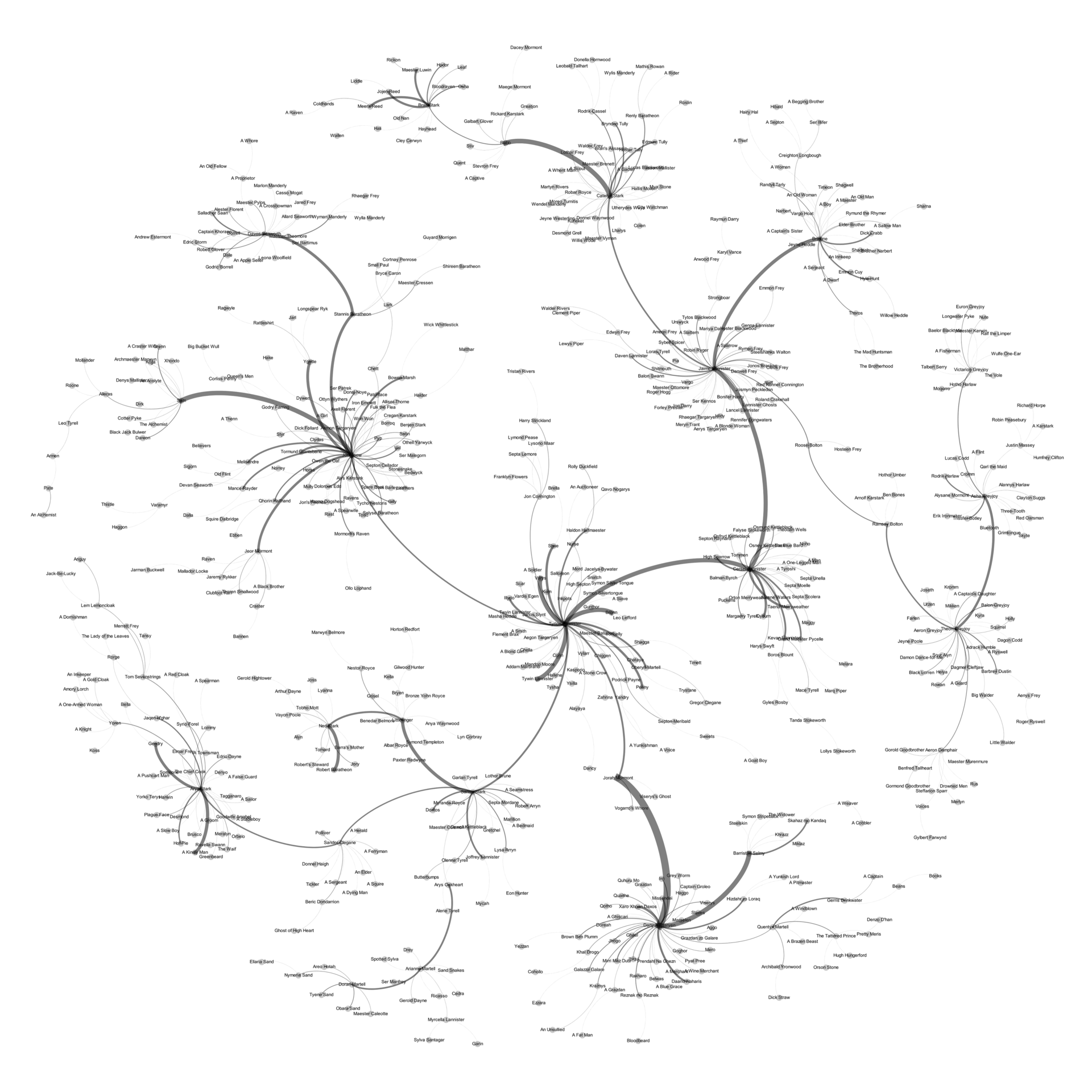
Начнём, конечно же, с главного — данных. У нас есть граф социальной активности:

На нём изображены персонажи из мира престолов в вершинах графа, где размер вершины зависит от сказанных им слов, и диалогов персонажей на ребрах графа, где толщина ребра зависит от количества состоявшихся разговоров.
Общие сведения о графе:
Граф неориентированный.
Вершин (читай персонажей): 1105
Рёбер (читай диалогов): 3505
Это всё хорошо, но кто же составил список всех разговоров, да еще и определил их принадлежность спросите вы меня (в 5ти книгах ведь почти 2 миллиона слов). Метод условных случайных полей, отвечу я. Да, для сбора данных было привлечено машинное обучение и, как заявляет «тренер» модели, точность определения принадлежности разговора составляет около 75%. Я добавлю опросник в конце статьи, чтобы узнать стоит ли переводить эту статью о том как метод условных случайных полей был применен.
Итак, формат входных данных для всех алгоритмов будет одинаковый:
Первая строка содержит V и E, количество вершин и ребер в графе соответственно.
Далее идут V строк с ID персонажа и его именем. После этого E строк вида u v w — описание рёбер. Означает, что между u и v есть ребро с весом w, где u и v это ID персонажа. Напомню, что вес означает количество диалогов между соответствующими персонажами. Вес самих вершин учитываться нигде не будет, т.к. не нашёл достойного ему применения. Ах да, код алгоритмов будет представлен на языке C++.
Нам, конечно же, нужно считать данные. Для этого я создал файлы definitions.h и definitions.cpp. Далее я везде буду подключать definitions.h чтобы кода было меньше и код читался легче. Каждый последующий алгоритм реализован как отдельная функция и вызывается в функции main.
#ifndef DEF_H
#define DEF_H
#define _CRT_SECURE_NO_DEPRECATE
#include <cstdio>
#include <iostream>
#include <string>
#include <vector>
#include <map>
#include <algorithm>
#include <queue>
#include <set>
#include <iterator>
#include <functional>
using namespace std;
extern int reverseID[];
extern vector<int> id;
extern vector< vector<int> > weight, edge;
extern map<int, string> name;
extern int V, E;
void read_data();
#endif
#include "definitions.h"
int reverseID[3000];
vector<int> id; // origin ID of characters
vector< vector<int> > weight; // weights of edges
vector< vector<int> > edge; // the graph's edges
map<int, string> name; // names of characters
int V, E; // amount of vertices and edges
void read_data() {
freopen("input.in", "r", stdin); // read from the input file
cin >> V >> E;
id.resize(V);
weight.resize(V);
edge.resize(V);
int u;
char s[100];
for (int i = 0; i < V; i++) { // read the names
scanf("%d %[^n]", &u, s);
name[i] = string(s);
id[i] = u; // origin ID by assigned ID
reverseID[u] = i; // assigned ID by origin ID
}
int a, b, w;
for (int i = 0; i < E; i++) { // read the edges and weights
cin >> a >> b >> w;
edge[reverseID[a]].push_back(reverseID[b]);
edge[reverseID[b]].push_back(reverseID[a]);
weight[reverseID[a]].push_back(w);
weight[reverseID[b]].push_back(w);
}
}
#include "definitions.h"
#include "degree.h"
#include "dfsbfs.h"
#include "bridges_articulations.h"
#include "cliques.h"
#include "spanning.h"
#include "cut.h"
int main() {
read_data();
degree();
count_components();
calculate_diameter();
find_cliques();
get_spanning_tree();
find_bridges_and_articulations();
find_cut();
}
Степень вершины
Для начала, попробуем реализовать что нибудь очень простое, что даже стыдно назвать алгоритмом, но будет интересно читателю/зрителю. Найдём степень каждой вершины. Степень вершины — это количество рёбер, инцидентных (примыкающих к) вершине. Этот параметр в контексте графа, который мы имеем, покажет нам сколько же «друзей» у персонажа.
Это можно сделать за один проход и сложность этого алгоритма О(V+E). Если применить и сортировку результата, как это сделал я, то сложность будет O(E+V*log(V)).
#include "definitions.h"
void degree() {
freopen("degree.txt", "w", stdout); // output file
vector< pair<int,int> > degree(V);
for (int i = 0; i < V; i++) {
degree[i] = make_pair(edge[i].size(), i);
}
stable_sort(degree.begin(), degree.end());
for (int i = V-1; i >= 0; i--) {
cout << name[degree[i].second] << ": " << degree[i].first << endl;
}
}
Топ 10 многосвязных персонажей:
- Тирион Ланнистер: 168
- Джон Сноу: 128
- Арья Старк: 104
- Джейми Ланнистер: 102
- Серсея Ланнистер: 86
- Кейтилин Старк: 85
- Теон Грейджой: 76
- Дайнерис Таргариен: 73
- Бриенна: 71
- Санса Старк: 69
Интересно то, что в топе не оказалось того, кто знаком со многими и по занимаемой должности обязан поддерживать контакт с людьми, Вариса (он на 25ом месте). А вот, казалось бы, второстепенный персонаж Бриенна, от имени которой главы еще нет, на 9ом месте.
Обход графа
Итак, теперь перейдем к простым алгоритмам, а именно к поиску в глубину (Depth-first search) и поиску в ширину (Breadth-first search). Оба алгоритма очень похожи, различаются только способом обхода графа. Они применяются, когда требуется пройти по рёбрам от заданной вершины в графе до другой. В случае поиска в глубину, граф проходится начиная от вершины и поочередно в максимальную глубину по одному из исходящих рёбер. В случае же с поиском в ширину граф обходится сначала по всем своим соседним вершинам, далее по соседям соседних вершин и так пока не пройденных вершин не останется. Оба алгоритма имеют сложность O(V+E).
Связность графа
Найдём компоненты связности нашего графа. Компонента связности это подграф, у которого все вершины имеют путь до любой другой вершины компоненты. Для этого запустим алгоритм поиска в глубину по одному из вершин, а после завершения, в следующей, не помеченной алгоритмом, вершине. Таким образом каждый запуск поиска будет означать новую компоненту связности.
#include "definitions.h"
vector<bool> useddfs;
vector<int> comp;
void dfs(int u) {
useddfs[u] = true;
comp.push_back(u);
for (vector<int>::iterator i = edge[u].begin(); i != edge[u].end(); i++)
if (!useddfs[*i])
dfs(*i);
}
void count_components() {
freopen("components.txt", "w", stdout); // output file
int comp_num = 0;
useddfs.resize(V, false);
for (int i = 0; i < V; i++) {
if (!useddfs[i]) {
comp.clear();
dfs(i);
comp_num++;
}
}
cout << comp_num;
}
Было бы крайне странно, если бы граф был не связным и в нём было больше одной компоненты, не правда ли? Но к моему удивлению в графе оказалось аж 3 компоненты! Но посмотрев на них я увидел, что присутствовала одна большая компонента, и 2 другие, в которых было по одному персонажу (Это были улыбающийся старик (A smiley old man), который разговаривал с Арьей возле Божьего ока (God’s eye). И повар (A Cook), который играл с Тирионом на корабле). Ничего необычного, у них нет имён и удивительно, что участники разговора вообще определились правильно. Я, конечно же, добавил недостающие рёбра и в результате весь граф получился связным.
Теория рукопожатий
Следующее что мы найдем с помощью алгоритма поиска уже в ширину — максимальное число рукопожатий в графе, другими словами диаметр графа, т.е наидлиннейший из кратчайших путей между всеми вершинами графа. Как оказалось, максимальное количество рукопожатий это 8. Неплохой результат для произведения о «средневековых веках», если учитывать Теорию 6ти рукопожатий. Для примера, одна из таких цепочек связи:
Матушка Кротиха (Mother Mole) — Репейница (Thistle) — Варамир (Varamyr) — Джон Сноу (Jon Snow) — Эддард Старк (Ned Stark) — Барристан Селми (Barristan Selmy) — Квентин Мартелл (Quentyn Martell) — Принц-Оборванец (The Tattered Prince) — Льюис Ланстер (Lewis Lanster)
Такой алгоритм работает за O(V*V+V*E). Так как нужно запустить алгоритм BFS из каждой вершины графа. Будь этот граф деревом, то потребовалось бы только 2 раза запустить BFS. Сначала из любой вершины графа, а затем из самой отдалённой от неё вершины. И наибольшая глубина последнего запуска и была бы диаметром графа.
А раз я нашёл самые длинные пути для всех вершин графа, то можно вычислить и среднее значение, а так же составить распределение максимальных путей. Среднее значение для длины максимальных путей оказалось 6,16 (в среднем вполне вписывается в теорию о 6ти рукопожатиях), а общее среднее расстояние 3,6, для сравнения у фейсбука этот параметр 4.57.
Распределение длин максимальных путей:

Если взглянуть на распределение то мы видим что 77 персонажей находятся «в центре» графа, иными словами они могут связаться с любым другим персонажем не более чем через 4х других. Среди них все основные персонажи истории, кроме Дайнерис Таргариен и Сансы Старк, а среди тех, кому в книгах посвящено меньше пяти глав попали в список Барристан Селми, Джон Коннингтон и Мелисандра.
#include "definitions.h"
vector<bool> usedbfs;
void bfs(int u, vector<int> &distance, vector<int> &path) {
queue<int> q;
q.push(u);
usedbfs[u] = true;
path[u] = -1;
while (!q.empty()) {
int u = q.front();
q.pop();
for (vector<int>::iterator i = edge[u].begin(); i != edge[u].end(); i++) {
int to = *i;
if (!usedbfs[to]) {
usedbfs[to] = true;
q.push(to);
distance[to] = distance[u] + 1;
path[to] = u;
}
}
}
}
void calculate_diameter() {
freopen("diameter.txt", "w", stdout); // output file
int diameter = 0;
int current_max = 0;
double average_max = 0;
double average_average = 0;
vector< vector<int> > distribution(V, vector<int> (0));
vector< vector<int> > max_path;
vector<int> farthest_node;
for (int i = 0; i < V; i++) {
vector<int> distance_to(V, 0);
vector<int> path(V,-1);
usedbfs.clear();
usedbfs.resize(V, false);
bfs(i, distance_to, path);
current_max = 0;
for (int j = 0; j < V; j++) {
average_average += distance_to[j];
if (distance_to[j] > current_max)
current_max = distance_to[j];
if (distance_to[j] > diameter) {
diameter = distance_to[j];
farthest_node.clear();
max_path.clear();
max_path.push_back(path);
farthest_node.push_back(j);
} else if (distance_to[j] == diameter){
max_path.push_back(path);
farthest_node.push_back(j);
}
}
average_max += current_max;
distribution[current_max].push_back(i);
}
average_max /= V;
average_average /= V*V;
cout << "Diameter: " << diameter << endl;
cout << "Average path: " << average_average << endl;
cout << "Average farthest path: " << average_max << endl;
vector < vector<int> > farthest_path;
for (int i = 0; i < farthest_node.size(); i++) {
farthest_path.push_back(vector<int>());
for (int u = farthest_node[i]; u != -1; u = max_path[i][u])
farthest_path[i].push_back(u);
}
cout << "Farthest paths:" << endl;
for (int i = 0; i < farthest_path.size(); i++) {
cout << i+1 << ": ";
for (vector<int>::iterator j = farthest_path[i].begin(); j != farthest_path[i].end(); j++)
cout << name[*j] << ". ";
cout << endl;
}
int minimum = V;
cout << "Farthest paths distribution:" << endl;
for (int i = 0; i <= diameter; i++) {
if (distribution[i].size() != 0 && i < minimum)
minimum = i;
cout << i << ": " << distribution[i].size() << endl;
}
cout << "Characters with minimum farthest path:" << endl;
for (vector<int>::iterator i = distribution[minimum].begin(); i != distribution[minimum].end(); i++) {
cout << name[*i] << endl;
}
}
Клики в графе
Алгоритм Брона-Кербоша позволяет найти максимальные клики в графе, иными словами подмножества вершин, любые две из которых связаны ребром. В контексте рассматриваемого графа это позволит найти сильно связанные компании, которые общались между собой в истории. Сложность алгоритма линейна относительно количества клик в графе, но в худшем случае она экспоненциальна O(3V/3), алгоритм решает NP полную задачу всё таки. Сам по себе алгоритм представляет рекурсивную функцию, которая для каждой вершины находит максимальную клику, т.е. такую, в которую нельзя добавить ни одной другой вершины. Итак, результаты:
Распределение размеров клик:

Как видно, максимальная клика размером в 9 персонажей. К примеру одна из таких — компания Ланнистеров: Тирион, Джейми, Серсея, Варис, Тайвин, Кеван, Пицель, Петир и Мейс Тирелл. Что интересно, все клики размера 8 и 9 сформированы в Королевской Гавани или вблизи неё. А максимальная клика с Дайнерис размера 5.
#include "definitions.h"
vector < vector<int> > cliques;
bool compare_vectors_by_size(const vector<int> &i, const vector<int> &j)
{
return (i.size() > j.size());
}
void bron_kerbosch(set <int> R, set <int> P, set <int> X) { // where R is probable clique, P - possible vertices in clique, X - exluded vertices
if (P.size() == 0 && X.size() == 0) { // R is maximal clique
cliques.push_back(vector<int>(0));
for (set<int>::iterator i = R.begin(); i != R.end(); i++) {
cliques.back().push_back(*i);
}
}
else {
set <int> foriterate = P;
for (set<int>::iterator i = foriterate.begin(); i != foriterate.end(); i++) {
set <int> newR;
set <int> newP;
set <int> newX;
newR = R;
newR.insert(*i);
set_intersection(P.begin(), P.end(), edge[*i].begin(), edge[*i].end(), inserter(newP, newP.begin()));
set_intersection(X.begin(), X.end(), edge[*i].begin(), edge[*i].end(), inserter(newX, newX.begin()));
bron_kerbosch(newR, newP, newX);
P.erase(*i);
X.insert(*i);
}
}
}
void find_cliques() {
freopen("cliques.txt", "w", stdout); // output file
set <int> P;
for (int i = 0; i < V; i++) {
P.insert(i);
stable_sort(edge[i].begin(), edge[i].end());
}
bron_kerbosch(set<int>(), P, set<int>());
stable_sort(cliques.begin(), cliques.end(), compare_vectors_by_size);
cout << "Distribution:" << endl;
int max_size = 0;
int max_counter = 0;
for (int i = cliques.size()-1; i >= 0 ; i--) {
if (cliques[i].size() > max_size) {
if (max_counter > 0) {
cout << max_size << ": " << max_counter << endl;
}
max_size = cliques[i].size();
max_counter = 0;
}
max_counter++;
}
if (max_counter > 0) {
cout << max_size << ": " << max_counter << endl;
}
cout << "Cliques:" << endl;
for (int i = 0; i < cliques.size(); i++) {
cout << i + 1 << "(" << cliques[i].size() << "): ";
for (int j = 0; j < cliques[i].size(); j++) {
cout << name[cliques[i][j]] << ". ";
}
cout << endl;
}
}
Остовное дерево
А теперь немного упростим наш граф связей, оставив в нём только «костяк», так называемое остовное дерево, т.е. наиболее важные рёбра связи и при этом превратив граф в дерево со всеми исходными вершинами. Поможет нам в этом алгоритм Крускала. Алгоритм жадный, для его осуществления нужно всего лишь отсортировать все рёбра по их весу и поочередно добавлять каждое ребро, если оно связывает две компоненты. Если использовать правильную структуру данных (обычно используют систему непересекающихся множеств), то сложность алгоритма получится O(E(logE)+V+E) = O(E(logV)). Ниже приведен результат графа, который подвергся этим манипуляциям. Я так же для читаемости удалил рёбра с весом 1.

картинка кликабельна
Итак, из этого графа можно увидеть главных героев и их связь между собой. Как я и ожидал, Тирион Ланнистер находится в «центре» всех связей, от него исходят 4 большие ветки: Серсея Ланнистер, Джон Сноу, Санса Старк и Джорах Мормонт (ветка Дайнерис). Последние в свою очередь герои следующего уровня по связям. Вполне ожидаемый результат, не правда ли?
#include "definitions.h"
vector<int> p;
int dsu_get(int v) {
return (v == p[v]) ? v : (p[v] = dsu_get(p[v]));
}
void dsu_unite(int u, int v) {
u = dsu_get(u);
v = dsu_get(v);
if (rand() & 1)
swap(u, v);
if (u != v)
p[u] = v;
}
void get_spanning_tree() {
freopen("spanning.txt", "w", stdout); // output file
vector < pair < int, pair<int, int> > > edges_weights, result;
vector < vector<bool> > used;
for (int i = 0; i < V; i++) {
used.push_back(vector<bool>(V, false));
}
for (int i = 0; i < V; i++) {
for (int j = 0; j < edge[i].size(); j++) {
int cur_v = edge[i][j];
if (!used[i][cur_v]) {
edges_weights.push_back(make_pair(weight[i][j], make_pair(i, cur_v)));
used[i][cur_v] = true;
used[cur_v][i] = true;
}
}
}
sort(edges_weights.begin(), edges_weights.end(), greater< pair < int, pair<int, int> > >());
for (int i = 0; i < V; i++) {
p.push_back(i);
}
for (int i = 0; i < E; i++) {
int u = edges_weights[i].second.first;
int v = edges_weights[i].second.second;
int w = edges_weights[i].first;
if (dsu_get(u) != dsu_get(v)) {
result.push_back(edges_weights[i]);
dsu_unite(u, v);
}
}
for (vector < pair < int, pair<int, int> > >::iterator i = result.begin(); i != result.end(); i++) {
cout << id[(i->second).first] << " " << id[(i->second).second] << " " << i->first << endl;
}
}
А вот сколько всего остовных деревьев, включая не только максимальные можно построить? Неимоверно много в данном графе, разумеется. Но их можно подсчитать используя теорему Кирхгофа. Теорема говорит, что если построить матрицу, где все элементы матрицы смежности будут заменены на противоположные, а на главной диагонали будут стоять степени соответствующих вершин, то все алгебраические дополнения полученной матрицы будут равны и это значение будет количеством остовных деревьев графа.
Мосты и шарниры
Мостами в графе называют рёбра, при удалении которых, количество компонент связности увеличивается. Аналогичное определение и у шарниров, только в отличии от мостов, шарниры это вершины, при удалении которых количество компонент связности возрастает. В данном графе, наличие мостов будет означать что в мире престолов существуют связи, которые являются единственным источником коммуникации между отдельными группами персонажей. Шарниры же, это герои, которые являются единственным посредником к группе других персонажей. Мосты и шарниры искать не очень тяжело. Для этого нам понадобится знакомый нам алгоритм поиска в глубину, но слегка модифицированный. Нужно использовать, так называемое, время входа в вершину и функцию времени выхода (fout) на вершине, которая будет принимать значения минимума времени входа и значений fout вершины в которую поиск в глубину пройден, таким образом, если при проходе ребра окажется, что значение функции fout на вершине больше чем время захода в неё, то это будет мостом, а так же и шарниром, а если равно, то только шарниром. Иными словами мы проверяем, возвращаемся ли мы после обхода в то же самое ребро/вершину и только в неё при обходе части графа, если да, то это и будет искомым мостом либо шарниром.
Как и ожидалось, все шарниры и мосты охватывали только малозначимых персонажей. Количество вершин в компонентах, которые получилось бы изолировать, удалением шарниров и мостов, не превышает 4х. Это означает, что нет героя, которым бы невозможно было пожертвовать. Все связаны между собой как минимум через двух других персонажей.
#include "definitions.h"
vector<bool> used, usedcnt;
int timer = 0;
vector<int> tin, fout, articulations;
vector < pair<int,int> > bridges;
int count_rec(int v, int skip) {
int cnt = 1;
usedcnt[v] = true;
for (int i = 0; i < edge[v].size(); i++) {
int to = edge[v][i];
if(to == skip || usedcnt[to])
continue;
cnt += count_rec(to, skip);
}
return cnt;
}
int count_from(int v, int skip, bool clean = true){
usedcnt.resize(V, false);
if (clean) {
for (int i = 0; i < usedcnt.size(); i++)
usedcnt[i] = false;
}
return count_rec(v, skip);
}
void dfs(int v, int prev = -1) {
used[v] = true;
tin[v] = fout[v] = timer++;
int root_calls = 0;
bool in_ar_list = false;
for (int i = 0; i < edge[v].size(); i++) {
int to = edge[v][i];
if (to == prev) continue;
if (used[to])
fout[v] = min(fout[v], tin[to]);
else {
dfs(to, v);
fout[v] = min(fout[v], fout[to]);
if (fout[to] > tin[v]) {
bridges.push_back(make_pair(v, to));
}
if (fout[to] >= tin[v] && prev != -1 && !in_ar_list) {
articulations.push_back(v);
in_ar_list = true;
}
root_calls++;
}
}
if (prev == -1 && root_calls > 1)
articulations.push_back(v);
}
void find_bridges_and_articulations() {
freopen("bridges_and_articulations.txt", "w", stdout); // output file
used.resize(V, false);
tin.resize(V);
fout.resize(V);
for (int i = 0; i < V; i++)
if (!used[i])
dfs(i);
cout << "Bridges:" << endl;
for (int i = 0; i < bridges.size(); i++) {
cout << name[bridges[i].first] << " (" << count_from(bridges[i].first, bridges[i].second) << ") - " << name[bridges[i].second] << " (" << count_from(bridges[i].second, bridges[i].first) <<")" << endl;
}
cout << endl << "Articulation points:" << endl;
for (int i = 0; i < articulations.size(); i++) {
int cur = articulations[i];
cout << name[cur];
for (int i = 0; i < usedcnt.size(); i++)
usedcnt[i] = false;
for (int j = 0; j < edge[cur].size(); j++) {
if (!usedcnt[edge[cur][j]]) {
int comp_size = count_from(edge[cur][j], cur, false);
cout << " (" << comp_size << ")";
}
}
cout << endl;
}
}
Минимальный разрез
Но всё же интересно узнать, сколько героев требуется «убить» чтобы полностью исключить контакт двух самых популярных (по вышеизложенной статистике) персонажей, скажем, Тириона Ланнистера и Арью Старк, либо Джона Сноу и Серсею Ланнистер. Для этого будем использовать алгоритм Диница. Для начала разберёмся как работает алгоритм.
По теореме Форда-Фалкерсона следует, что величина максимального потока в графе путей равна величине пропускной способности его минимального разреза. Иными словами, мы можем найти минимальный разрез между двумя вершинами (сток и исток) если найдём максимальный поток между этими вершинами. Алгоритм Диница как раз позволяет найти величину максимального потока и, собственно, сам поток. Я не буду разбирать подробно сам алгоритм и предоставлю вам возможность самим разобраться в нём. Для понимания полученного результата достаточно знать, что поток — это некая функция, которая для каждого ребра лежащего на пути от истока к стоку, определяет положительную величину, не превышающую пропускную способность этого ребра. Для упрощения можно представить систему труб с водой, где объем воды протекающей от истока к стоку в момент t и есть величина потока.
Поставленная мною задача слегка отличается от той, что решает алгоритм. Дело в том, что поток определяется на рёбрах, и если мы найдём минимальный разрез, то он «разрежет» граф по рёбрам, т.е. связям в графе, но нам ведь нужно разрезать граф не по рёбрам, а вершинам, т.е. персонажам. Чтобы решить эту задачу нужно подвергнуть граф небольшим изменениям. Раздвоим каждую вершину в графе, скажем вместо вершины v у нас получатся вершины v1 и v2, далее если между двумя вершинами v и u было ребро, то перенаправим v1 в u2, а u1 в v2, вместо ребра (u, v) получатся рёбра (v1, u2) и (u1, v2). И между каждыми раздвоенными вершинами v1 и v2 проведём ребро (v2, v1). В полученном, уже ориентированном, графе, все связи сохранятся, но там где раньше были вершины, появятся рёбра. Если вес этих ребер будет 1, а у всех остальных, скажем бесконечность (на практике можно использовать количество вершин в графе), то ребро между раздвоенными вершинами будет слабым звеном в графе и по принципу «предохранителя» не позволит пройти бОльшему потоку через себя, что даст возможность узнать количество вершин, которые нужно удалить, чтобы граф стал несвязным. А дальше запустим алгоритм Диница на полученном графе.
Сложность алгоритма O(n2m). Поэтому мы будем искать величину максимального потока не по всем парам вершин, а только по персонажам, которые имеют наибольшее количество связей, иначе для данного графа сложность получится O(n5), где n=1000 и работать всё будет много часов. Ниже я приведу результаты по топ 100 персонажам по связям.
Я немного удивился результатам. Оказалось, что в топ 100, разрезать граф можно избавившись от минимум 6ти персонажей. Все такие связи при этом содержат либо Джона Коннингтона либо Эурона Грейджоя в качестве стока/истока. Но это не основные персонажи. Что интересно, в топ 10ти, в основном минимальный поток равен около 45ти. Например между Тирионом и Арьей поток равен 53, а между Джоном Сноу и Серсеей 42. Но есть и персонаж, которого можно отделить, удалив 16 других персонажей. Это Дайнерис Таргариен, не удивительно, ведь она наиболее удалённая героиня на карте престолов.
Ещё интересно было бы узнать, кто же наиболее «важный» герой в потоках. Т.е. через кого чаще всего протекает максимальный поток. Тут есть чему удивиться. Топ 10 важных персонажей в потоках (в скобках соответствующее количество вхождений в потоки):
- Тирион Ланнистер (4109)
- Джейми Ланнистер (3067)
- Арья Старк (3021)
- Джон Сноу (2883)
- Эддард Старк (2847)
- Серсея Ланнистер (2745)
- Теон Грейджой (2658)
- Бриенна (2621)
- Сандор Клегане (2579)
- Санса Старк (2573)
Во первых, Эддард Старк был важным персонажем и их, к несчастью (или к счастью) не жалеют. Во вторых, Бриенна, от имени которой не написано ни одной главы, всё же важный персонаж. В третьих, топ 10 персонажей весьма живучи, во всяком случае пока, но самое интересное, что следующие 10 персонажей это:
11. Джофрей Ланнистер
12. Робб Старк
13. Ренли Баратеон
14. Кейтилин Старк
15. Русе Болтон
16. Йорен
17. Сэм
18. Мелисандра
19. Бран Старк
20. Варис
где верхние 6 персонажей уже убиты. Не позавидуешь этой десятке.
Так же, благодаря потокам, удалось вычислить «лишние» вершины, авторов реплик которых не удалось правильно распознать, поэтому они были связаны со многими персонажами, с которыми не должны были пересекаться. Ими оказались Человек (A Man) и Страж (A Guard). В следствии чего, я удалил эти вершины и пересчитал всю статистику заново.
#include "definitions.h"
const int INF = 1000000000;
struct edge_s{
int a, b, c, flow; // a->b, c-capacity, flow=0
edge_s(int a, int b, int c, int flow) : a(a), b(b), c(c), flow(flow) {}
};
vector< pair<int, int> > top_degree;
vector< pair<int, int> > top_flow;
vector<int> dis;
vector<int> ptr;
vector<edge_s> edgelist;
vector< vector<int> > edges_dup;
bool compare_pairs_by_second(const pair<int, int> &i, const pair<int, int> &j)
{
return (i.second > j.second);
}
bool bfs_dinic(int s, int t) {
queue<int> q;
q.push(s);
dis[s] = 0;
while (!q.empty() && dis[t] == -1) {
int v = q.front();
q.pop();
for (int i = 0; i < edges_dup[v].size(); i++) {
int ind = edges_dup[v][i],
next = edgelist[ind].b;
if (dis[next] == -1 && edgelist[ind].flow < edgelist[ind].c) {
q.push(next);
dis[next] = dis[v] + 1;
}
}
}
return dis[t] != -1;
}
int dfs_dinic(int v, int t, int flow) {
if (!flow) {
return 0;
}
if (v == t) {
return flow;
}
for (; ptr[v] < (int) edges_dup[v].size(); ptr[v]++) {
int ind = edges_dup[v][ptr[v]];
int next = edgelist[ind].b;
if (dis[next] != dis[v] + 1) {
continue;
}
int pushed = dfs_dinic(next, t, min(flow, edgelist[ind].c - edgelist[ind].flow));
if (pushed) {
edgelist[ind].flow += pushed;
edgelist[ind ^ 1].flow -= pushed;
return pushed;
}
}
return 0;
}
long long dinic_flow(int s, int t) {
long long flow = 0;
while (true) {
fill(dis.begin(), dis.end(), -1);
if (!bfs_dinic(s, t)) {
break;
}
fill(ptr.begin(), ptr.end(), 0);
while (int pushed = dfs_dinic(s, t, INF)) {
flow += pushed;
}
}
return flow;
}
void dinic_addedge(int a, int b, int c) {
edges_dup[a].push_back((int) edgelist.size());
edgelist.push_back(edge_s(a, b, c, 0));
edges_dup[b].push_back((int) edgelist.size());
edgelist.push_back(edge_s(b, a, 0, 0));
}
void find_cut() {
freopen("cut_min.txt", "w", stdout); // output file
dis.resize(2 * V, 0);
ptr.resize(2 * V, 0);
edges_dup.resize(2 * V, vector<int>(0));
const int top = min(10, V);
for (int i = 0; i < V; i++)
top_flow.push_back(make_pair(0, i));
for (int i = 0; i < V; i++) {
top_degree.push_back(make_pair(edge[i].size(), i));
for (int j = 0; j < edge[i].size(); j++) {
int to = edge[i][j];
dinic_addedge(i, to + V, V);
}
dinic_addedge(i + V, i, 1);
}
stable_sort(top_degree.rbegin(), top_degree.rend());
cout << "Minimum cut between characters:" << endl;
for (int i = 0; i < top; i++) {
for (int j = i + 1; j < top; j++) {
vector<int>::iterator p = find(edge[top_degree[i].second].begin(), edge[top_degree[i].second].end(), top_degree[j].second);
if (p != edge[top_degree[i].second].end())
continue;
int flow = dinic_flow(top_degree[i].second, top_degree[j].second + V);
cout << name[top_degree[i].second] << " -> " << name[top_degree[j].second] << " = " << flow << endl;
for (int k = 0; k < edgelist.size(); k++) {
if ((edgelist[k].a == (edgelist[k].b + V)) && (edgelist[k].flow == 1)) {
top_flow[edgelist[k].b].first++;
}
edgelist[k].flow = 0;
}
}
}
stable_sort(top_flow.rbegin(), top_flow.rend());
cout << endl << "Top involved characters in the flows:" << endl;
for (int i = 0; i < top; i++) {
cout << name[top_flow[i].second] << " (" << top_flow[i].first << ")" << endl;
}
}
На этом всё. Напоследок можно отметить, что Тирион Ланнистер очень важный персонаж в мире престолов. Надеюсь, статься оказалась для вас интересной, а возможно и полезной. Исходный код всех алгоритмов есть так же и на GitHub, ссылки ниже.
Ссылки:
Проект на GitHub
Исходный социальный граф
Программа Gephi, с помощью которого можно открыть проект
Автор фото заголовка — Adam Foster
В конце, как и обещал, опросник: стоит ли переводить статью о том, как были определены авторы диалогов в книгах?
Автор: A3a







{kind=link}