Последовательное A-B-тестирование в Netflix. Часть 2: процессы подсчёта
Сталкивались вы когда-нибудь с ошибкой при просмотре потокового видео на Netflix? Может — неожиданно останавливался или вовсе не запускался фильм, который вас заинтересовал? В первой части [1] этой серии статей мы рассказали о методологии тестирования канареечных релизов, применяемой к показателям, которые представлены непрерывными потоками данных. Среди таких показателей — «задержка воспроизведения» (play‑delay). Вот комментарий одного из читателей:
А что если выход нового релиза не связан с изменениями в функционале воспроизведения и потоковой передачи видео? Например — что если в новом релизе будет изменено что-то, ответственное за вход пользователя в систему? Тестируя такой релиз вы, как и в других случаях, так же будете наблюдать за метрикой «задержка воспроизведения»?
В Netflix наблюдают за множеством метрик, многие из которых можно отнести к классу «счётных». В их число входят такие показатели, как количество входов в систему, ошибок, успешных запусков воспроизведения видео и даже количество обращений пользователя в колл-центр. В этом материале мы опишем методологию последовательного статистического анализа, применяемую нами для исследования счётных метрик. Она представлена в нашей статье «Anytime-Valid Inference For Multinomial Count Data [2]», вышедшей в материалах конференции NeurIPS.

Найдите отличия
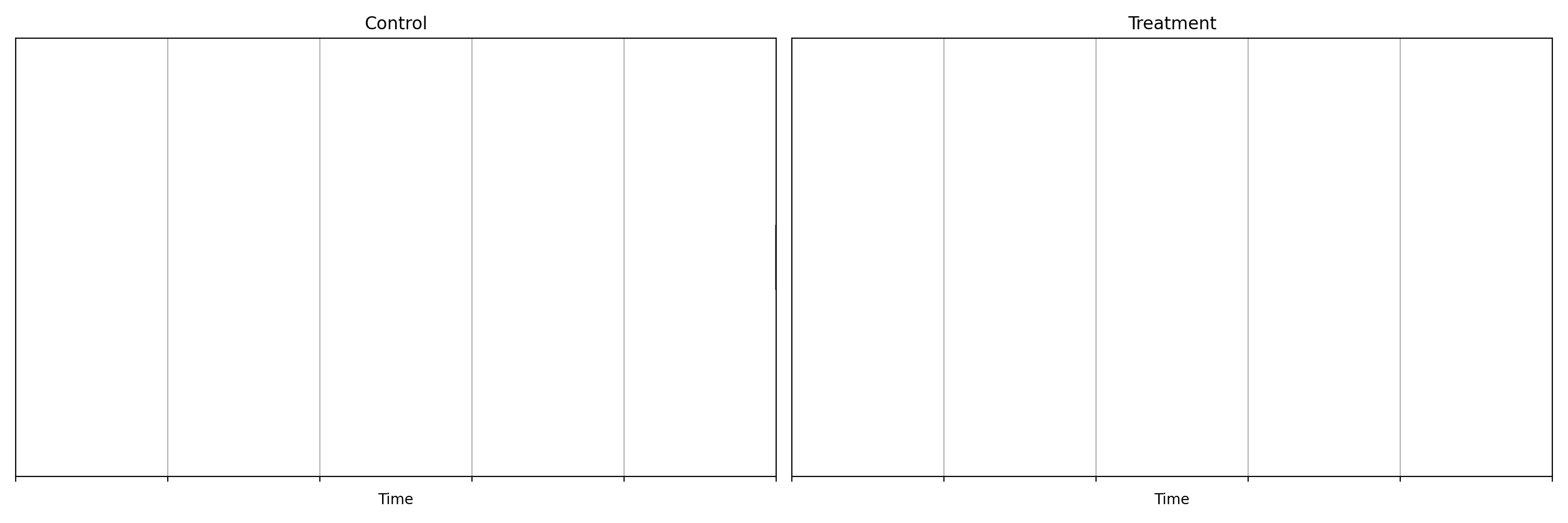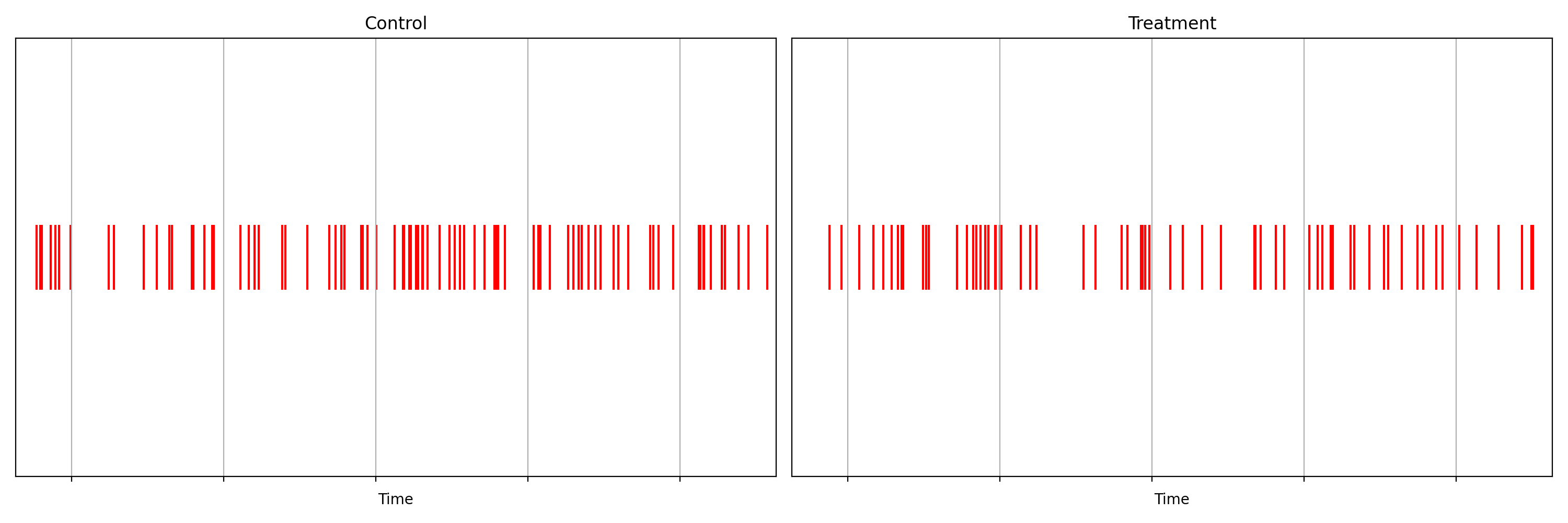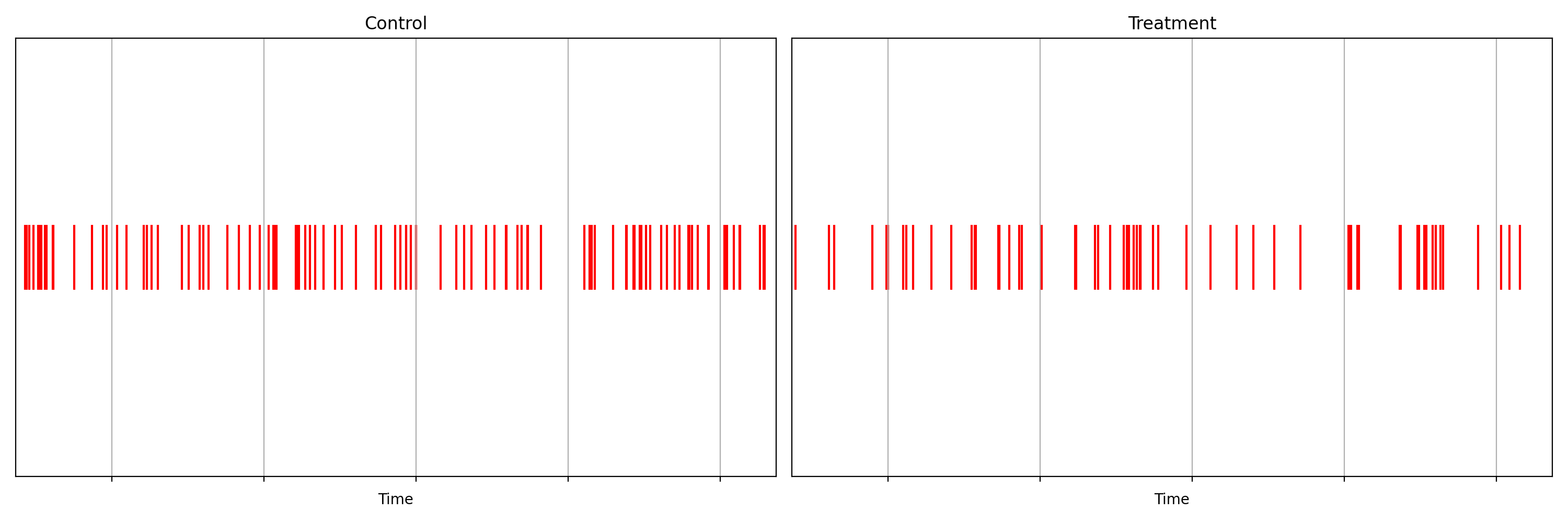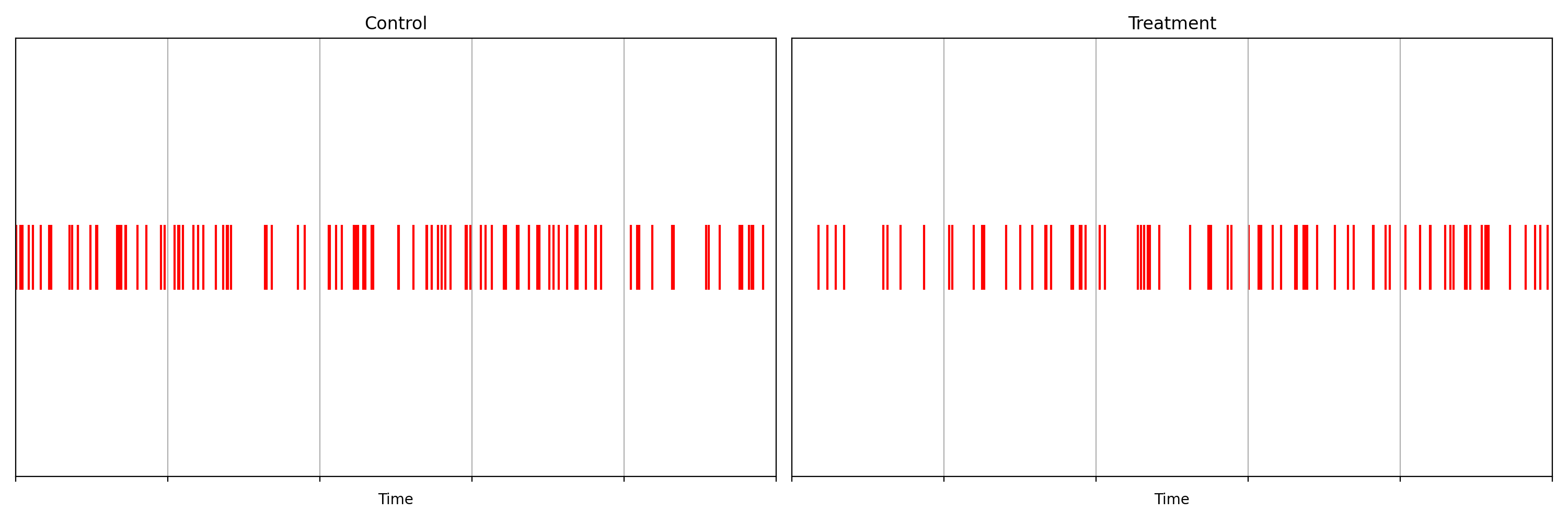
Предположим, мы собираемся развернуть новую версию клиента, в которой изменено поведение механизма входа в систему. Для того чтобы снизить риски, связанные с новым кодом, мы проводим его A/B-тестирование, известное ещё как «тестирование канареечного релиза». Когда происходит некое событие, такое, как вход в систему, в журнал записываются сведения о нём, в частности — отметка времени. Эти сведения попадают в журнал в реальном времени, проходя через соответствующую бэкенд-систему. На рис. 1 показана последовательность временных меток, сгенерированных устройствами, на которых работает новый код (экспериментальная группа пользователей) и код, используемый в настоящее время (контрольная группа). Вот — вопрос, на который мы, что вполне естественно, хотим ответить с помощью этих данных: не происходит ли в экспериментальной группе меньше входов в систему, чем в контрольной группе? Можете на него ответить?
Гифка на 12 Мб [3]
Рис. 1. Отметки времени, описывающие события, происходящие в контрольной (слева) и экспериментальной (справа) группах пользователей.
{kind=link}
Ответ на этот вопрос не дашь, просто посмотрев на бегущие линии, представленные на рисунке. Но разница становится совершенно очевидной при визуализации [4] наблюдаемых нами счётных процессов (рис. 2).

Счётный процесс — это функция, значение которой увеличивается на 1 при поступлении нового события. Теперь понятно, что в экспериментальной группе произошло меньше событий, чем в контрольной. Если бы речь шла о событиях входа в систему, то такие данные могли бы указывать на то, что в новом коде есть ошибка, которая мешает некоторым пользователям успешно войти в систему.
Это — обычная ситуация, возникающая при работе с временными метками событий. Вот ещё пример: если события представляют ошибки или серьёзные сбои — нам хотелось бы знать о том, как соотносится скорость накопления таких событий в экспериментальной и контрольной группах. А именно — о том, накапливаются ли они в экспериментальной группе быстрее, чем в контрольной. Более того — нам хотелось бы давать ответы на подобные вопросы настолько быстро, насколько это возможно. Так, в случае возникновения проблем, мы сможем оперативно предотвратить любое дальнейшее ухудшение качества работы наших служб. Всё это обуславливает необходимость применения последовательного статистического анализа, о котором мы говорили в первом [1] материале этой серии.
Неоднородный процесс Пуассона
Наши данные для каждой экспериментальной группы представляют собой реализацию одномерного точечного процесса, то есть — последовательность отметок времени. Так как интенсивность поступления событий изменяется во времени (и в экспериментальной, и в контрольной группах), мы строим модель нашего точечного процесса на основе неоднородного процесса Пуассона [5]. Этот процесс определяется функцией интенсивности λ:R → [0, ∞). Количество событий в интервале [0,t), обозначаемое как N(t), имеет распределение Пуассона:
N(t) ~ Poisson(Λ(t)), где Λ(t) = ∫₀ᵗ λ(s) ds.
Мы хотим проверить нулевую гипотезу H₀: λᴬ(t) = λᴮ(t) для всех t, то есть — проверить то, что функции интенсивности для контрольной (A) и экспериментальной (B) групп одинаковы. Это можно сделать путём применения полупараметрической модели, не делая никаких предположений о функциях интенсивности λᴬ и λᴮ. Кстати говоря — новизна нашего исследования заключается в том, что сделать это можно в последовательном режиме, как описано в 4 разделе [6] публикации. Удобно то, что для проверки этой гипотезы на момент времени t нужны лишь Nᴬ(t) и Nᴮ(t), общее количество событий, произошедших до этого момента в контрольной и экспериментальной группах. Другими словами — для проверки нулевой гипотезы нужно лишь два целых числа, которые легко можно привести к актуальному состоянию по мере поступления новых событий. Вот — пример из симуляции A/A-теста, где нам известно, что контрольной (A) и экспериментальной (B) группам соответствует одна и та же, хотя и нестационарная, функция интенсивности.
 Симуляция A/A теста для двух неоднородных процессов Пуассона. (Справа) Последовательность доверительных интервалов, построенных с использованием разностей логарифмов функций интенсивности, и последовательное p-значение.")
На рис. 3. проиллюстрирован ход A/A-тестирования. Слева показаны исходные данные и функции интенсивности, справа — последовательный статистический анализ данных. Синий и красный графики-щётки показывают временные метки событий, поступивших, соответственно, из экспериментальной и контрольной групп. Пунктирные линии — это счётные процессы, за которыми организовано наблюдение. Так как в ходе симуляции выдаются данные, соответствующие нулевой гипотезе, функции интенсивности получаются идентичными и друг друга перекрывают. Левая ось в правой части рисунка используется для визуализации изменения доверительных интервалов, построенных с использованием разностей логарифмов функций интенсивности. На правой оси в правой части рисунка откладываются изменяющиеся показатели, иллюстрирующие последовательное p-значение. Здесь мы можем сделать два важных наблюдения:
-
При выдаче данных, соответствующих нулевой гипотезе, разница логарифмов функций интенсивности равна нулю. Это значение, как и ожидается, всё время пребывает в пределах 95% доверительных интервалов.
-
Последовательное p-значение всё время больше 0,05.
Теперь рассмотрим пример A/B-тестирования. На рис. 4 показаны наблюдения за поступлением событий для экспериментальной и контрольной групп в условиях, когда их функции интенсивности различаются. Так как это — симуляция — нам известно истинное различие между логарифмами функций интенсивности.
 Симуляция A/B теста для двух неоднородных процессов Пуассона. (Справа) Последовательность доверительных интервалов, построенных с использованием разностей логарифмов функций интенсивности, и последовательное p-значение.")
По результатам этого эксперимента можно сделать следующие выводы:
-
95% доверительные интервалы всё время включают в себя истинную разность логарифмов функций.
-
Показатель последовательного p-значения падает ниже 0,05 в то же самое время, когда в доверительный интервал перестаёт попадать нулевое значение, которое соответствует нулевой гипотезе.
Теперь мы представим вашему вниманию несколько практических примеров того, как, с помощью этой методологии, были быстро обнаружены серьёзные проблемы в некоторых «счётных» метриках.
Пример 1: падение показателя, отражающего успешный запуск воспроизведения видеоматериалов
На рис. 2, на самом деле, показан подсчёт событий запуска воспроизведения видеоматериалов из реального канареечного теста. Всякий раз, когда видео успешно запускается — с устройства в систему Netflix отправляется событие [7]. У нас имеется поток событий запуска воспроизведения видео, поступающий с устройств, входящих в экспериментальную группу, и такой же поток от устройств из контрольной группы. Когда мы фиксируем уменьшение количества успешных запусков видео на устройствах из экспериментальной группы — это обычно говорит о наличии в новом клиенте какой-то ошибки, препятствующей проигрыванию видеоматериалов.
В данном случае в ходе канареечного теста обнаружена ошибка, которая, как было выяснено позже, не даёт примерно 60% устройств из экспериментальной группы запускать потоковую передачу видео. На рис. 5 показана последовательность доверительных интервалов, там же можно видеть и p-значение (последовательное). Хотя мы и не приводим точные временные данные этого эксперимента, отметим, что эта ошибка обнаружена на временных интервалах длительностью менее одной секунды.

Пример 2: рост количества аварийных завершений работы клиентов
В дополнение к событиям, связанным с запуском воспроизведения видеоматериалов, нас интересуют и события, соответствующие неожиданной остановке работы клиента Netflix. Как и ранее — имеются два потока с событиями аварийного завершения работы клиента. Один — с устройств из экспериментальной группы, второй — с устройств из контрольной группы. Нижеприведённый скриншот — это реальная копия экрана одной из наших панелей управления Lumen [8].

Рис. 6 иллюстрирует два важных момента. Первый — хорошо видно, что поступлению событий аварийного завершения работы клиентов свойственна нестационарность. Второе — некумулятивное представление событий не позволяет чётко увидеть разницу между экспериментальной и контрольной группами. А вот кумулятивное представление событий значительно облегчает обнаружение этой разницы путём наблюдения за счётным процессом. Речь идёт о небольшом, но заметном увеличении количества аварийных завершений работы клиентов в экспериментальной группе. На Рис. 7 показано то, что наша методология последовательного статистического анализа способна обнаружить даже такие вот небольшие различия между потоками данных.
 Последовательность доверительных интервалов, построенных с использованием формулы λᴮ(t)/λᴬ(t) (синяя полоса), а так же — представление счётных процессов для экспериментальной (чёрная штриховая линия) и контрольной (синяя штриховая линия) групп. (Нижняя панель) Последовательные p-значения.")
Пример 3: рост количества ошибок
В Netflix, кроме того, наблюдают и за количеством ошибок, произошедших на устройствах, входящих в экспериментальную и контрольную группы. Это — метрика, отличающаяся высокой кардинальностью, так как сообщение о каждой ошибке снабжается кодом, описывающим тип ошибки. Мониторинг ошибок, разделённых на группы по кодам, помогает разработчикам быстро диагностировать проблемы. На рис. 8, на логарифмической шкале, показаны последовательные p-значения, построенные для группы кодов ошибок, за которыми в Netflix наблюдают во время выпуска клиента. В данном примере мы обнаружили большой объём ошибок с кодом 3.1.18 [9], выдаваемых устройствами из экспериментальной группы. Устройства, на которых происходит эта ошибка, выводят сообщение «We’re having trouble playing this title right now».

 и контрольной (красная линия) групп.")
Знание о том, каких именно ошибок стало больше, может значительно облегчить нашим разработчикам процесс отладки кода. Обнаружив нечто подобное, мы тут же оповещаем разработчиков, пользуясь средствами для взаимодействия со Slack, интегрированными в нашу платформу.

Когда будете смотреть видео на Netflix и встретитесь с ошибкой — знайте, что мы рядом!
Испытайте наши наработки!
Статистический подход, описанный в нашей публикации [6], невероятно легко реализовать на практике. Для этого понадобится всего лишь пара целых чисел — количество событий, зафиксированных на некий момент времени в экспериментальной и контрольной группах. Программный код, весьма компактный, можно найти здесь [10].
Вот — пара примеров его использования:
> counts = [100, 101]
> assignment_probabilities = [0.5, 0.5]
> sequential_p_value(counts, assignment_probabilities)
1
> counts = [100, 201]
> assignment_probabilities = [0.5, 0.5]
> sequential_p_value(counts, assignment_probabilities)
5.06061172163498e-06При этом данный код подходит и для случаев, когда количество групп, участвующих в эксперименте, превышает две. Подробности вы можете найти в 4 разделе [6] нашей публикации.
О, а приходите к нам работать? 🤗 💰
Мы в wunderfund.io [11] занимаемся высокочастотной алготорговлей [12] с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
Автор: mr-pickles
Источник [14]
Сайт-источник PVSM.RU: https://www.pvsm.ru
Путь до страницы источника: https://www.pvsm.ru/razrabotka/400115
Ссылки в тексте:
[1] первой части: https://habr.com/ru/companies/wunderfund/articles/850382/
[2] Anytime-Valid Inference For Multinomial Count Data: https://openreview.net/forum?id=a4zg0jiuVi
[3] Гифка на 12 Мб: https://miro.medium.com/v2/resize:fit:720/format:webp/1*AGdASLgCaQCNo72VV7rOFg.gif
[4] визуализации: https://en.wikipedia.org/wiki/Counting_process#:~:text=Counting%20processes%20deal%20with%20the,be%20a%20Markov%20counting%20process.
[5] процесса Пуассона: https://en.wikipedia.org/wiki/Poisson_point_process#Inhomogeneous_Poisson_point_process
[6] 4 разделе: https://openreview.net/pdf?id=a4zg0jiuVi
[7] событие: https://netflixtechblog.com/sps-the-pulse-of-netflix-streaming-ae4db0e05f8a
[8] Lumen: https://netflixtechblog.com/lumen-custom-self-service-dashboarding-for-netflix-8c56b541548c
[9] 3.1.18: https://help.netflix.com/en/node/100573?q=3.1.18
[10] здесь: https://gist.github.com/michaellindon/5ce04c744d20755c3f653fbb58c2f4dd
[11] wunderfund.io: http://wunderfund.io/
[12] высокочастотной алготорговлей: https://en.wikipedia.org/wiki/High-frequency_trading
[13] Присоединяйтесь к нашей команде: http://wunderfund.io/#join_us
[14] Источник: https://habr.com/ru/companies/wunderfund/articles/852194/?utm_campaign=852194&utm_source=habrahabr&utm_medium=rss
Нажмите здесь для печати.