

Каждый из нас слышал о концепции программно-определяемых сетей (Software Defined Networking, SDN). Однако, несмотря на непрерывное развитие и ряд значительных изменений, эта концепция долгое время не имела воплощения в виде коммерчески состоявшихся продуктов, по сути, оставаясь на уровне «Slides Defined», т. е. в виде умозрительных конструкций в презентациях вендоров и интеграторов. В свете этого неудивительно, что чрезмерно активное обсуждение темы SDN в последние годы вкупе с отсутствием полностью рабочих решений на рынке привело если не к отторжению, то точно к критическому отношению к этой технологии со стороны части ИТ-сообщества. В данной статье мы хотели бы развеять этот скепсис и рассказать о сетевой фабрике, которая соответствует классическим критериям SDN и в то же время является полностью законченным, «коробочным» решением.
Статья призвана рассказать об архитектуре решения, его особенностях, а также о личных впечатлениях от тестирования. В процессе подготовки материала хотелось показать, насколько простым и удобным может быть SDN для построения ЦОД, поэтому мы сознательно будем избегать глубокого погружения в технику и больше акцентируем внимание на возможностях, которые может принести данное решение. Ввиду большого объема материала мы разбили его на 3 части: общее описание и архитектура, функциональность и возможности интеграции.
Вместо вступления
В отличие от устоявшихся технологий построения распределенных корпоративных и кампусных сетей, подходы к организации сети ЦОД постоянно развиваются. Отчасти это связано со значительным ростом требований со стороны приложений и смежных систем. Так, для работы приложений необходима все большая пропускная способность, ужесточаются требования к предсказуемости задержки, а также различным параметрам передачи трафика, что приводит к пересмотру применяемых механизмов и топологий. Смежные системы (в частности, системы виртуализации и оркестрации), в свою очередь, требуют более широких возможностей по интеграции и автоматизации, позволяющих влиять на процессы, происходящие в сети.
Концепция Software Defined Networking призвана решить большинство проблем с интеграцией и автоматизацией за счет использования единой точки управления и контроля сети. Эти же принципы должны помочь значительно снизить зависимость пользователя от вендора — до сих пор в сетевом мире производитель, как правило, является единственным поставщиком ПО к своему оборудованию, несмотря на то, что оборудование создается на базе типовых элементов, производимых сторонними компаниями.
В свою очередь, развитие рынка специальных микросхем (ASIC) и производителей аппаратной части привело к появлению на рынке коммутаторов без фирменного программного обеспечения (т.н.BM-коммутаторы), для которых обеспечивающая основную функциональность операционная система разрабатывается другими компаниями. Стоимость таких коммутаторов значительно ниже, чем у их брендированных аналогов, и у клиента появляется возможностью выбора операционной системы. Но, к сожалению, подавляющее большинство таких SDN-продуктов представляет из себя некий конструктор, предлагающий самостоятельно собрать решение из доступных частей (коммутаторов, контроллеров, ПО). Возможно, использование подобных наборов приемлемо для компаний, обладающих значительным штатом технических специалистов, но для большинства организаций такой подход неудобен.
Между тем недавно нашей компании удалось протестировать решение по построению сети ЦОД Big Cloud Fabric (BCF) от компании Big Switch Networks, которое отличается куда большей дружественностью по отношению к пользователю. Big Cloud Fabric является классическим SDN-решением: в нем используются BM-коммутаторы в качестве аппаратной инфраструктуры сетевой фабрики и централизованный Control Plane, вынесенный на отдельный контроллер. На контроллер возлагаются функции расчета топологии, обработки маршрутной информации, изучения подключенных хостов, а также конфигурирования и управления всеми функциями системы. Результаты работы контроллера синхронизируются между коммутаторами и напрямую заносятся в аппаратные таблицы ASIC. И при этом BCF является полностью законченным, «коробочным» решением, которое не требует от пользователя долгих и трудных процессов интеграции компонентов между собой.
 Компания Big Switch Networks основана в 2010 г. командой разработчиков концепции SDN из Стэнфордского университета. Являясь признанным пионером отрасли, с 2013 года компания разрабатывать SDN-решения с применением BM-коммутаторов. Продуктовый портфель представлен двумя системами: Big Cloud Fabric (сетевая фабрика ЦОД) и Big Fabric Monitoring (пакетный брокер). Компания отмечена множеством наград в области виртуализации, а также облачных и SDN-технологий.
Компания Big Switch Networks основана в 2010 г. командой разработчиков концепции SDN из Стэнфордского университета. Являясь признанным пионером отрасли, с 2013 года компания разрабатывать SDN-решения с применением BM-коммутаторов. Продуктовый портфель представлен двумя системами: Big Cloud Fabric (сетевая фабрика ЦОД) и Big Fabric Monitoring (пакетный брокер). Компания отмечена множеством наград в области виртуализации, а также облачных и SDN-технологий.Давайте подробнее рассмотрим, как работает решение на основе столь нетипичного подхода и какие возможности оно может предложить для пользователей.
Архитектура Big Cloud Fabric
Что из себя представляет Big Cloud Fabric? Если попробовать коротко сформулировать определение, то наиболее подходящим будет следующее: BСF – это сеть передачи данных ЦОД с возможностью использования BM-коммутаторов, находящихся под единым контролем, и обладающая единым интерфейсом взаимодействия для управления, аналитики и интеграции.
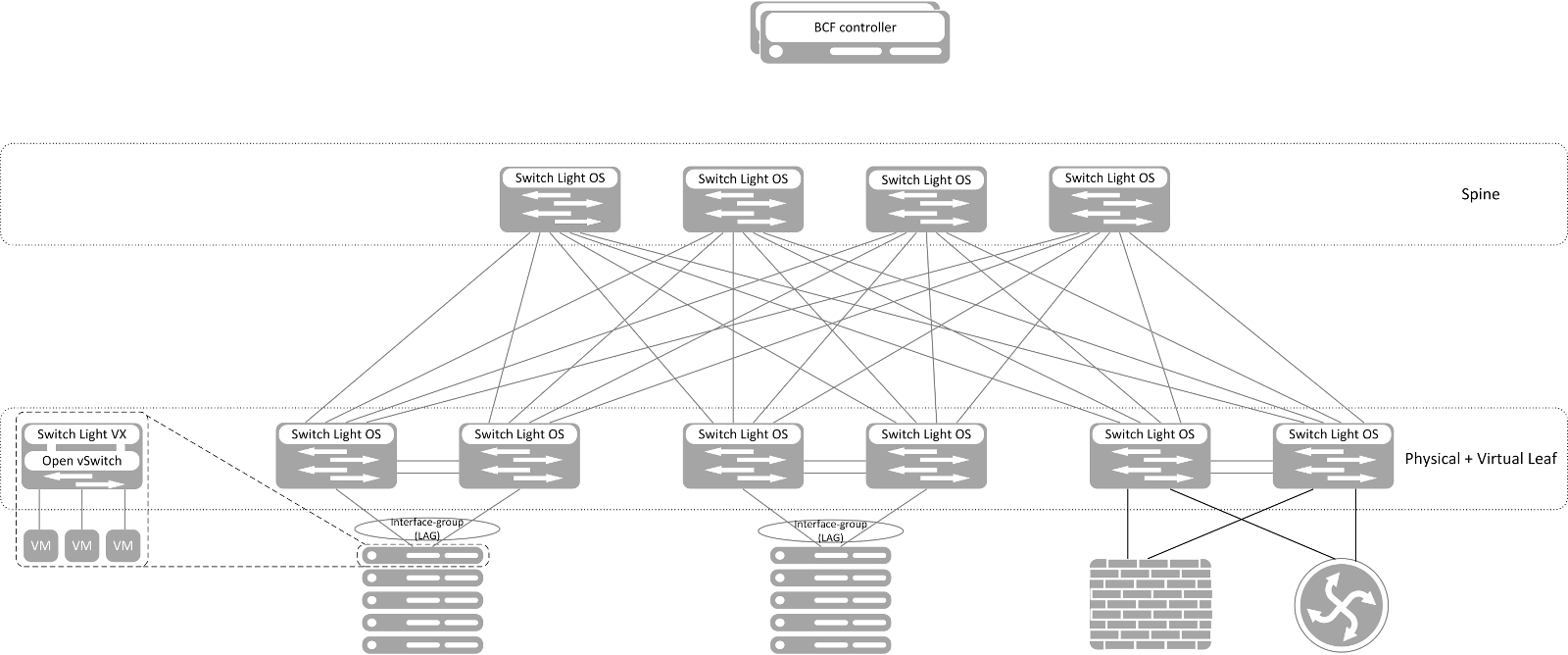
В основе BCF лежит сеть Ethernet-коммутаторов, построенная по топологии Spine and Leaf, которая в настоящее время является наиболее востребованной для построения сетей ЦОД. Дополнительно, любые два leaf коммутатора могут быть объединены в MC-LAG пару (Leaf Group в терминологии BCF).
Однако в отличие от других решений, в BCF можно использовать коммутаторы разных производителей, поддерживающие установку сетевых операционных систем. С технической точки зрения, эти коммутаторы ничем не отличаются от привычных, брендированных моделей. Они используют те же самые аппаратные компоненты – центральный процессор, память и коммерчески доступный ASIC. Однако вместо операционной системы производители BM-коммутаторов устанавливают загрузчик ONIE – небольшую системную утилиту, которая обеспечивает загрузку и установку любой совместимой сетевой операционной системы. Подобный подход дает значительную гибкость при построении сети, поскольку обеспечивает возможность выбора аппаратной платформы независимо от используемого программного обеспечения.
В фабрике могут поддерживаться любые коммутаторы, построенные на ASIC Broadcom Trident II/II+ и Tomahawk, что составляет большинство производимых на данный момент коммутаторов ЦОД (как классических, так и Bare-metal/White Box). В официальный список поддерживаемых моделей входят различные коммутаторы Dell Networks и Accton/Edge-Core. Это связано с тем, что Big Cloud Fabric – это не набор коммутаторов, независимо работающих друг с другом, а единая фабрика, имеющая централизованное управление и контроль. Именно поэтому протестированная совместимость всех компонентов чрезвычайно важна для безотказной работы всей сети. Вместе с тем компания Big Switch Networks регулярно пополняет список поддерживаемых коммутаторов.
Коммутаторы сами по себе бесполезны без операционной системы, которая могла бы ими управлять. В случае BCF все элементы управления, контроля и интеграции со сторонними системами вынесены на специальное устройство – контроллер фабрики. В его задачи входят все функции управления и контроля — предоставление интерфейса доступа к фабрике, сбор информации о подключенных хостах, расчет топологии, синхронизация информации для программирования аппаратных таблиц между коммутаторами, а также многое другое. На коммутаторы устанавливается легковесная операционная система Switch Light OS, которая предназначена для получения инструкций от контроллера и непосредственного программирования их в ASIC коммутатора, а также сбора «сырых» данных статистики и отправки их на контроллер для анализа. При этом сетевому администратору не нужно вручную устанавливать ОС на коммутатор – BCF поддерживает механизм Zero Touch Provisioning, благодаря которому коммутатор после подключения к сети управления, автоматически определяется контроллером, на него устанавливается ОС и шаблоны конфигурации. Информация между коммутаторами и контроллером передается посредством сильно видоизмененного протокола OpenFlow.
Если проводить напрашивающуюся аналогию с модульным коммутатором, то коммутаторы — это линейные карты (leaf) и коммутационные модули (spine), а контроллер – супервизор большого территориально распределённого коммутатора. Для обеспечения отказоустойчивости, фабрикой управляет кластер из минимум 2 узлов, а сеть взаимодействия между контроллером и коммутаторами реализуется в виде отдельной, out of band инфраструктуры.
Big Cloud Fabric доступна в двух вариантах: полностью физической фабрики (P Fabric) и гибридной (P+V Fabric). Последний вариант предлагает возможность установки программного агента Switch Light VX (по сути, той же Switch Light OS) для программных коммутаторов Open vSwitch в виртуальной среде KVM. Switch Light VX работает в пользовательском окружении и не оказывает никакого влияния на ядро гипервизора. В его задачи входит синхронизация политик пересылки трафика с контроллером фабрики и реализация их в Open vSwitch. Фактически, в BM-коммутаторах Swith Light OS опирается на «мускулы» ASIC, а в виртуальной среде – на ЦП и Open vSwitch. Таким образом, благодаря наличию агента в виртуальной среде, не только оптимизируется пересылка трафика (коммутация и маршрутизация между виртуальными машинами выполняется на физическом хосте, без передачи на внешнее устройство), но и появляется возможность применения политик и сбора аналитики в виртуальной среде.
На данный момент реализация P+V Fabric возможна только в архитектуре OpenStack/KVM, поскольку она является открытой. Для других гипервизоров доступна P Fabric. Однако возможности по интеграции с VMware vCenter/vSphere (о которых ниже) полностью компенсируют данные неудобства.
{kind=link}

Структурная схема Big Cloud Fabric (изображение кликабельно)
Необходимо еще раз отметить, что в отличие от похожих продуктов других производителей, контроллер является элементом, который полностью управляет коммутаторами фабрики, производит расчеты топологии, отношений соседства протоколов маршрутизации с внешними устройствами и синхронизирует состояния аппаратных таблиц. Это не система управления, которая лишь собирает конфигурационные данные и на их основании настраивает коммутаторы. Это не система мониторинга, периодически (или по запросу) опрашивающая устройства и собирающая лишь ту информацию, которую они могут предоставить по стандартным протоколам. Это настоящий Control Plane фабрики — контроллер имеет полную картину сети, поскольку он сам ее создает. Через ОС на коммутаторах он имеет доступ напрямую к ASIC, и именно поэтому скорость реакции у BCF выше, а аналитика на порядок подробнее чем у конкурирующих продуктов.
В связи с такой значимой ролью контроллера в инфраструктуре фабрики возникает резонный вопрос: что будет, если все элементы кластера выйдут из строя и фабрика останется без Control Plane? Как оказывается, ничего страшного и не произойдет. Оставшись без контроллера (headless mode) фабрика продолжит работать в обычном режиме и будет корректно обрабатывать трафик уже изученных хостов, и даже некоторые виды отказов (например, отказ линка в пределах одной стойки (MC-LAG пары)). Конечно, данный режим накладывает ограничения на новые настройки, изучение вновь подключаемых хостов и изменения топологии фабрики – т.е. они обработаны не будут. Кому-то это может показаться недостатком, однако давайте представим, что произойдет, в случае отказа всех супервизоров в модульном коммутаторе? Вероятнее всего он просто остановится.
Автор: aleks_shi