

У всех есть любимые книжки про магию. У кого-то это Толкин, у кого-то — Пратчетт, у кого-то, как у меня, Макс Фрай. Сегодня я расскажу вам о моей любимой IT-магии — о BPF и современной инфраструктуре вокруг него.
BPF сейчас на пике популярности. Технология развивается семимильными шагами, проникает в самые неожиданные места и становится всё доступнее и доступнее для обычного пользователя. Почти на каждой популярной конференции сегодня можно услышать доклад на эту тему, и GopherCon Russia не исключение: я представляю вам текстовую версию моего доклада.
В этой статье не будет уникальных открытий. Я просто постараюсь показать, что такое BPF, на что он способен и как может помочь лично вам. Также мы рассмотрим особенности, связанные с Go.
Я бы очень хотел, чтобы после прочтения моей статьи у вас зажглись глаза так, как зажигаются глаза у ребёнка, впервые прочитавшего книгу о Гарри Поттере, чтобы вы пришли домой или на работу и попробовали новую «игрушку» в деле.
Что такое eBPF?
Итак, о какой такой магии вам тут собирается рассказывать 34-летний бородатый мужик с горящими глазами?
Мы с вами живём в 2020 году. Если вы откроете Твиттер, то прочитаете твиты ворчливых господ, которые утверждают, что софт сейчас пишется такого ужасного качества, что проще всё это выкинуть и начать заново. Некоторые даже грозятся уйти из профессии, так как не могут это больше терпеть: всё постоянно ломается, неудобно, медленно.

Возможно, они правы: без тысячи комментов мы это не выясним. Но с чем я точно соглашусь, так это с тем, что современный софтверный стек как никогда сложен.
BIOS, EFI, операционная система, драйвера, модули, библиотеки, сетевое взаимодействие, базы данных, кеши, оркестраторы типа K8s, контейнеры типа Docker, наконец, наш с вами софт с рантаймами и сборщиками мусора. Настоящий профессионал может отвечать на вопрос о том, что происходит после того, как вы вбиваете ya.ru в браузере, несколько дней.
Понять, что происходит в вашей системе, особенно если в данный момент что-то идёт не так и вы теряете деньги, очень сложно. Эта проблема привела к появлению бизнес-направлений, призванных помочь разобраться в том, что происходит внутри вашей системы. В больших компаниях есть целые отделы «шерлоков», которые знают, куда стукнуть молотком и какую гайку подтянуть, чтобы сэкономить миллионы долларов.
Я на собеседованиях часто спрашиваю людей, как они будут дебажить проблемы, если их разбудить в четыре часа ночи.
Один из подходов — проанализировать логи. Но проблема в том, что доступны только те, которые заложил в свою систему разработчик. Они не гибкие.
Второй популярный подход — изучить метрики. Три самые популярные системы для работы с метриками написаны на Go. Метрики очень полезны, однако, позволяя увидеть симптомы, они не всегда помогают понять причины.
Третий подход, набирающий популярность, — так называемый observability: возможность задавать сколь угодно сложные вопросы о поведении системы и получать ответы на них. Так как вопрос может быть очень сложным, для ответа может понадобиться самая разная информация, и пока вопрос не задан, мы не знаем какая. А это значит, что observability жизненно необходима гибкость.
Дать возможность менять уровень логирования на лету? Приконнектиться дебаггером к работающей программе и что-то там сделать, не прерывая её работу? Понять, какие запросы поступают в систему, визуализировать источники медленных запросов, посмотреть, на что уходит память через pprof, и получить график её изменения во времени? Замерить latency одной функции и зависимость latency от аргументов? Все эти подходы я отнесу к observability. Это набор утилит, подходов, знаний, опыта, которые вместе дадут вам возможность сделать если не всё что угодно, то очень многое «наживую», прямо в работающей системе. Современный швейцарский IT-ножик.

Но как это реализовать? Инструментов на рынке было и есть много: простых, сложных, опасных, медленных. Но тема сегодняшней статьи — BPF.
Ядро Linux — event-driven-система. Практически всё, что происходит в ядре, да и в системе в целом, можно представить в виде набора событий. Прерывание — событие, получение пакета по сети — событие, передача процессора другому процессу — событие, запуск функции — событие.
Так вот, BPF — это подсистема ядра Linux, дающая возможность писать небольшие программы, которые будут запущены ядром в ответ на события. Эти программы могут как пролить свет на происходящее в вашей системе, так и управлять ею.
Это было очень длинное вступление. Приблизимся же немного к реальности.
В 1994 году появилась первая версия BPF, с которой некоторые из вас наверняка сталкивались, когда писали простые правила для утилиты tcpdump, предназначенной для просмотра, или сниффанья сетевых пакетов. tcpdump можно было задать «фильтры», чтобы видеть не все, а только интересующие вас пакеты. Например, «только протокол tcp и только порт 80». Для каждого проходящего пакета запускалась функция, чтобы решить, нужно сохранять этот конкретный пакет или нет. Пакетов может быть очень много — это значит, что наша функция должна быть очень быстрой. Наши tcpdump фильтры как раз преобразовывались в BPF-функции, пример которой виден на картинке ниже.

Простенький фильтр для tcpdump представлен в виде BPF-программы
Оригинальный BPF представлял собой совсем простенькую виртуальную машину с несколькими регистрами. Но, тем не менее, BPF значительно ускорила фильтрацию сетевых пакетов. В свое время это был большой шаг вперед.

В 2014 году Алексей Старовойтов расширил функциональность BPF. Он увеличил количество регистров и допустимый размер программы, добавил JIT-компиляцию и сделал верификатор, который проверял программы на безопасность. Но самым впечатляющим было то, что новые BPF-программы могли запускаться не только при обработке пакетов, но и в ответ на многочисленные события ядра, и передавали информацию туда-сюда между kernel и user space.
Эти изменения открыли возможности для новых вариантов использования BPF. Некоторые вещи, которые раньше реализовывались путём написания сложных и опасных модулей ядра, теперь делались относительно просто через BPF. Почему это круто? Да потому что любая ошибка при написании модуля часто приводила к панике. Не к пушистой Go-шной панике, а к панике ядра, после которой — только ребут.
У обычного пользователя Linux появилась суперспособность заглядывать «под капот», ранее доступная только хардкорным разработчикам ядра или недоступная никому. Эта опция сравнима с возможностью без особых усилий написать программу для iOS или Android: на старых телефонах это было или невозможно, или значительно сложнее.
Новая версия BPF от Алексея получила название eBPF (от слова extended — расширенная). Но сейчас она заменила все старые версии BPF и стала настолько популярной, что для простоты все называют её просто BPF.
Где используют BPF?
Итак, что же это за события, или триггеры, к которым можно прицепить BPF-программы, и как люди начали использовать новоприобретённую мощь?
На данный момент есть две большие группы триггеров.
Первая группа используется для обработки сетевых пакетов и для управления сетевым трафиком. Это XDP, traffic control-ивенты и ещё несколько.
Эти ивенты нужны, чтобы:
- Создавать простые, но очень эффективные файрволы. Компании вроде Cloudflare и Facebook с помощью BPF-программ отсеивают огромное количество паразитного трафика и борются с самыми масштабными DDoS-атаками. Так как обработка происходит на самой ранней стадии жизни пакета и прямо в ядре (иногда BPF-программа даже пушится сразу в сетевую карту для обработки), то таким образом можно обрабатывать колоссальные потоки трафика. Раньше такие вещи делали на специализированных сетевых железках.
- Создавать более умные, точечные, но всё ещё очень производительные файрволы — такие, которые могут проверить проходящий трафик на соответствие правилам компании, на паттерны уязвимостей и т. п. Facebook, например, занимается таким аудитом внутри компании, несколько проектов продают такого рода продукты наружу.
- Создавать умные балансировщики. Самым ярким примером является проект Cilium, который чаще всего используется в кластере K8s в качестве mesh-сети. Cilium управляет трафиком: балансирует, перенаправляет и анализирует его. И всё это — с помощью небольших BPF-программ, запускаемых ядром в ответ на то или иное событие, связанное с сетевыми пакетами или сокетами.
Это была первая группа триггеров, связанная с сетевыми вопросами и обладающая возможностью влиять на поведение. Вторая группа связана с более общим observability; программы из этой группы чаще всего не имеют возможности на что-то влиять, а могут только «наблюдать». Она интересует меня гораздо больше.
В данной группе есть такие триггеры, как:
- perf events — ивенты, связанные с производительностью и с Linux-профилировщиком perf: железные процессорные счётчики, обработка прерываний, перехват minor/major-исключений памяти и т. п. Например, вы можете поставить обработчик, который будет запускаться каждый раз, когда ядру надо вытащить из свопа какую-то страницу памяти. Представьте себе, например, утилиту, которая отображает программы, которые в данный момент используют своп.
- tracepoints — статические (определённые разработчиком) места в исходниках ядра, при прикреплении к которым можно достать статическую же информацию (ту, которую заранее подготовил разработчик). Может показаться, что в данном случае статичность — это плохо, ведь я говорил, что один из недостатков логов заключается в том, что они содержат только то, что изначально добавил программист. В каком-то смысле это так, но tracepoints обладают тремя важными преимуществами:
- их довольно много раскидано по ядру в самых интересных местах;
- когда они не включены, они не тратят ресурсы;
- они являются частью API, стабильны и не меняются, что очень важно, так как другие триггеры, о которых пойдёт речь, не имеют стабильного API.
В качестве примера можете представить себе утилиту, показывающую программы, которым ядро по той или иной причине не даёт время на выполнение, вы сидите и гадаете, почему она тормозит, а pprof при этом ничего интересного не показывает.
- USDT — то же самое, что tracepoints, только для user space-программ. То есть вы как программист можете добавлять такие места в свою программу. И многие крупные и известные программы и языки программирования уже обзавелись такими трейсами: MySQL, например, или языки PHP, Python. Часто они выключены по умолчанию и для их включения нужно пересобрать интерпретатор с параметром enable-dtrace или подобным. Да, в Go у нас тоже есть возможность регистрировать такие трейсы. Кто-то, может быть, узнал слово DTrace в названии параметра. Дело в том, что такого рода статические трейсы были популяризированы в одноимённой системе, которая зародилась в ОС Solaris: например, момент создания нового треда, запуска GC или чего-то, связанного с конкретным языком или системой.
Ну а дальше начинается ещё один уровень магии:
- ftrace-триггеры дают нам возможность запускать BPF-программу в начале практически любой функции ядра. Полностью динамически. Это значит, что ядро вызовет вашу BPF-функцию до начала выполнения любой выбранной вами функции ядра. Или всех функций ядра — как угодно. Вы можете прикрепиться ко всем функциям ядра и получить на выходе красивую визуализацию всех вызовов.
- kprobes/uprobes дают почти то же самое, что ftrace, только у нас есть возможность прицепиться к любому месту при исполнении функции как ядра, так и в user space. В середине функции есть какой-то if по переменной и вам надо построить гистограмму значений этой переменной? Не проблема.
- kretprobes/uretprobes — здесь всё аналогично предыдущим триггерам, но мы можем стриггернуться при завершении выполнения функции ядра и программы в user space. Такого рода триггеры удобны для просмотра того, что функция возвращает, и для замера времени её выполнения. Например, можно узнать, какой PID вернул системный вызов fork.
Самое замечательное в этом всём, повторюсь, то, что, будучи вызванной на любой из этих триггеров, наша BPF-программа может хорошенько «осмотреться»: прочитать аргументы функции, засечь время, прочитать переменные, глобальные переменные, взять стек-трейс, сохранить что-то на потом, передать данные в user space для обработки, получить из user space данные для фильтрации или какие-то управляющие команды. Красота!
Не знаю, как для вас, но для меня новая инфраструктура — как игрушка, которую я долго и трепетно ждал.
API, или Как это использовать
Окей, Марко, ты нас уговорил посмотреть в сторону BPF. Но как к нему подступиться?
Давайте посмотрим, из чего состоит BPF-программа и как с ней взаимодействовать.

Во-первых, у нас есть BPF-программа, которая, если пройдёт верификацию, будет загружена в ядро. Там она будет скомпилирована JIT в машинный код и запущена в режиме ядра, когда триггер, к которому она прикреплена, сработает.
У BPF-программы есть возможность взаимодействовать со второй частью — с user space-программой. Для этого есть два способа. Мы можем писать в циклический буфер, а user space-часть может из него читать. Также мы можем писать и читать в key-value-хранилище, которое называется BPF map, а user space-часть, соответственно, может делать то же самое, и, соответственно, они могут перекидывать друг другу какую-то информацию.
Прямолинейный путь
Самый простой способ работы с BPF, с которого ни в коем случае не надо начинать, состоит в написании BPF-программ на подобии языка C и компиляции данного кода с помощью компилятора Clang в код виртуальной машины. Затем мы загружаем этот код с помощью системного вызова BPF напрямую и взаимодействуем с нашей BPF-программой также с помощью системного вызова BPF.

Первое доступное упрощение — использование библиотеки libbpf, которая поставляется с исходниками ядра и позволяет не работать напрямую с системным вызовом BPF. По сути, она предоставляет удобные обёртки для загрузки кода, работы с так называемыми мапами для передачи данных из ядра в user space и обратно.
bcc
Понятно, что такое использование далеко от удобного для человека. Благо под брендом iovizor появился проект BCC, который значительно упрощает нам жизнь.

По сути, он готовит всё сборочное окружение и даёт нам возможность писать единые BPF-программы, где С-часть будет собрана и загружена в ядро автоматически, а user space-часть может быть сделана на простом и понятном Python.
bpftrace
Но и BCC выглядит сложным для многих вещей. Особенно люди почему-то не любят писать части на С.
Те же ребята из iovizor представили инструмент bpftrace, который позволяет писать BPF-скрипты на простеньком скриптовом языке а-ля AWK (либо вообще однострочники).

Знаменитый специалист в области производительности и observability Брендан Грегг подготовил следующую визуализацию доступных способов работы с BPF:

По вертикали у нас простота инструмента, а по горизонтали — его мощь. Видно, что BCC очень мощный инструмент, но не суперпростой. bpftrace гораздо проще, но при этом уступает в мощности.
Примеры использования BPF
Но давайте рассмотрим магические способности, которые стали нам доступны, на конкретных примерах.
И BCC, и bpftrace содержат папку Tools, где собрано огромное количество готовых интересных и полезных скриптов. Они одновременно являются и местным Stack Overflow, с которого вы можете копировать куски кода для своих скриптов.
Вот, например, скрипт, который показывает latency для DNS-запросов:
╭─marko@marko-home ~
╰─$ sudo gethostlatency-bpfcc
TIME PID COMM LATms HOST
16:27:32 21417 DNS Res~ver #93 3.97 live.github.com
16:27:33 22055 cupsd 7.28 NPI86DDEE.local
16:27:33 15580 DNS Res~ver #87 0.40 github.githubassets.com
16:27:33 15777 DNS Res~ver #89 0.54 github.githubassets.com
16:27:33 21417 DNS Res~ver #93 0.35 live.github.com
16:27:42 15580 DNS Res~ver #87 5.61 ac.duckduckgo.com
16:27:42 15777 DNS Res~ver #89 3.81 www.facebook.com
16:27:42 15777 DNS Res~ver #89 3.76 tech.badoo.com :-)
16:27:43 21417 DNS Res~ver #93 3.89 static.xx.fbcdn.net
16:27:43 15580 DNS Res~ver #87 3.76 scontent-frt3-2.xx.fbcdn.net
16:27:43 15777 DNS Res~ver #89 3.50 scontent-frx5-1.xx.fbcdn.net
16:27:43 21417 DNS Res~ver #93 4.98 scontent-frt3-1.xx.fbcdn.net
16:27:44 15580 DNS Res~ver #87 5.53 edge-chat.facebook.com
16:27:44 15777 DNS Res~ver #89 0.24 edge-chat.facebook.com
16:27:44 22099 cupsd 7.28 NPI86DDEE.local
16:27:45 15580 DNS Res~ver #87 3.85 safebrowsing.googleapis.com
^C%
Утилита в режиме реального времени показывает время выполнения DNS-запросов, так что вы сможете поймать, например, какие-то неожиданные выбросы.
А это скрипт, который «шпионит» за тем, что другие набирают на своих терминалах:
╭─marko@marko-home ~
╰─$ sudo bashreadline-bpfcc
TIME PID COMMAND
16:51:42 24309 uname -a
16:52:03 24309 rm -rf src/badooТакого рода скрипт можно использовать, чтобы поймать «плохого соседа» или провести аудит безопасности серверов компании.
Скрипт для просмотра флоу вызовов высокоуровневых языков:
╭─marko@marko-home ~/tmp
╰─$ sudo /usr/sbin/lib/uflow -l python 20590
Tracing method calls in python process 20590... Ctrl-C to quit.
CPU PID TID TIME(us) METHOD
5 20590 20590 0.173 -> helloworld.py.hello
5 20590 20590 0.173 -> helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.hello
5 20590 20590 2.175 -> helloworld.py.hello
5 20590 20590 2.176 -> helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.hello
^C%Здесь на примере показан стек вызовов программы на Python.
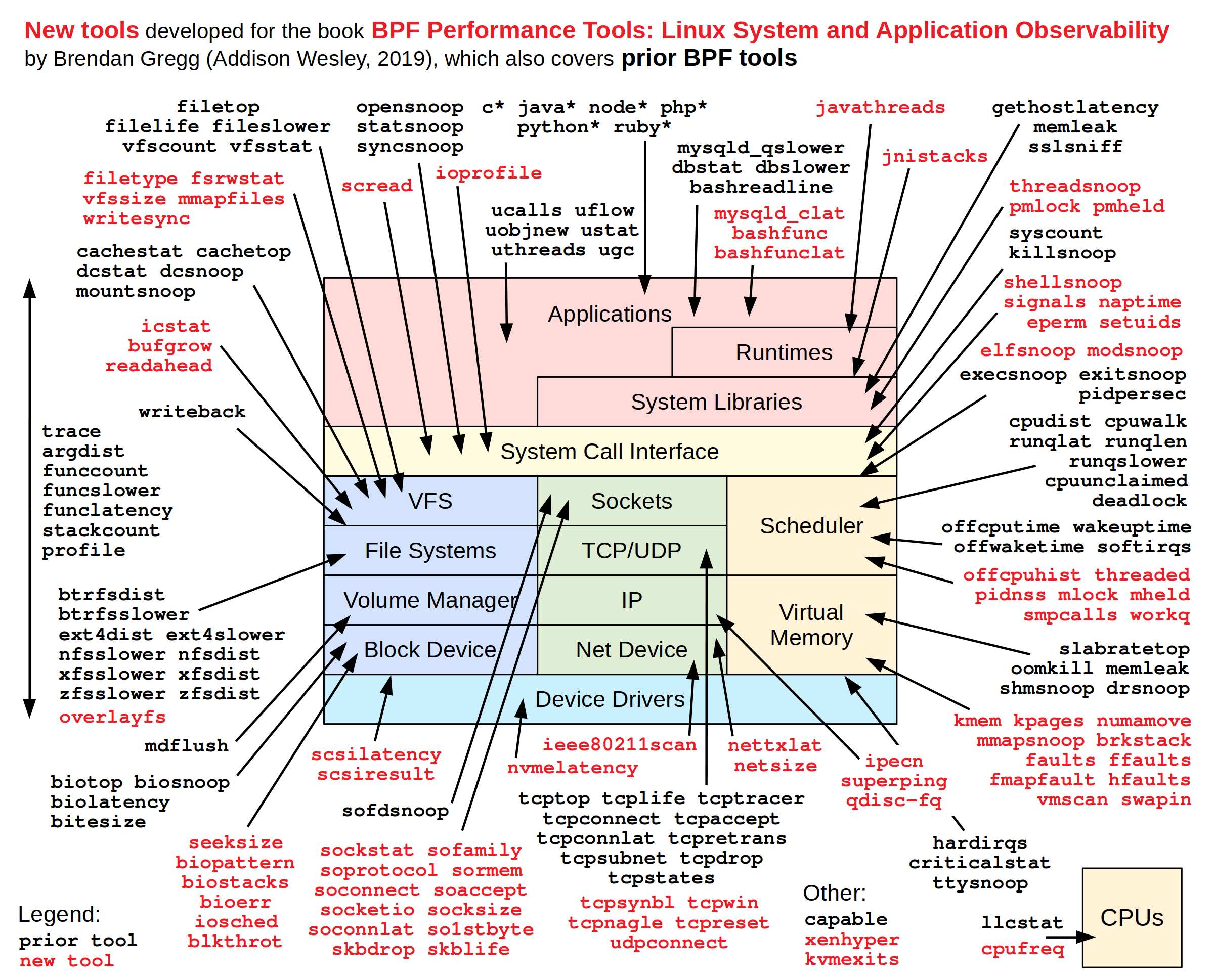
Тот же Брендан Грегг сделал картинку, на которой собрал все существующие скрипты со стрелочками, указывающими на те подсистемы, которые каждая утилита позволяет «обсёрвить». Как видно, нам уже доступно огромное количество готовых утилит — практически на любой случай.

Не пытайтесь что-то здесь углядеть. Картинка используется как справочник
А что у нас с Go?
Теперь давайте поговорим о Go. У нас два основных вопроса:
- Можно ли писать BPF-программы на Go?
- Можно ли анализировать программы, написанные на Go?
Пойдём по порядку.
На сегодняшний день единственный компилятор, который умеет компилировать в формат, понимаемый BPF-машиной, — Clang. Другой популярный компилятор, GСС, пока не имеет BPF-бэкенда. И единственный язык программирования, который может компилироваться в BPF, — очень ограниченный вариант C.
Однако у BPF-программы есть и вторая часть, которая находится в user space. И её можно писать на Go.
Как я уже упоминал выше, BCC позволяет писать эту часть на Python, который является первичным языком инструмента. При этом в главном репозитории BCC также поддерживает Lua и C++, а в стороннем — ещё и Go.

Выглядит такая программа точно так же, как программа на Python. В начале — строка, в которой BPF-программа на C, а затем мы сообщаем, куда прицепить данную программу, и как-то с ней взаимодействуем, например достаём данные из EPF map.
Собственно, все. Рассмотреть пример подробнее можно на Github.
Наверное, основной недостаток заключается в том, что для работы используется C-библиотека libbcc или libbpf, а сборка Go-программы с такой библиотекой совсем не похожа на милую прогулку в парке.
Помимо iovisor/gobpf, я нашёл ещё три актуальных проекта, которые позволяют писать userland-часть на Go.
- https://github.com/dropbox/goebpf
- https://github.com/cilium/ebpf
- https://github.com/andrewkroh/go-ebpf
Версия от Dropbox не требует никаких C-библиотек, но вот kernel-часть BPF-программы вам придётся собрать самостоятельно с помощью Clang и затем загрузить в ядро Go-программой.
Версия от Cilium имеет те же особенности, что версия от Dropbox. Но она стоит упоминания хотя бы потому, что делается ребятами из проекта Cilium, а значит, обречена на успех.
Третий проект я привёл для полноты картины. Как и два предыдущих, он не имеет внешних C-зависимостей, требует ручной сборки BPF-программы на C, но, похоже, не имеет особых перспектив.
На самом деле, есть ещё один вопрос: зачем вообще писать BPF-программы на Go? Ведь если посмотреть на BCC или bpftrace, то BPF-программы в основном занимают меньше 500 строк кода. Не проще ли написать скриптик на bpftrace-языке или расчехлить немного Python? Я тут вижу два довода.
Первый: вы ну очень любите Go и предпочитаете всё делать на нём. Кроме того, потенциально Go-программы проще переносить с машины на машину: статическая линковка, простой бинарник и всё такое. Но всё далеко не так очевидно, так как мы завязаны на конкретное ядро. Здесь я остановлюсь, а то моя статья растянется еще на 50 страниц.
Второй вариант: вы пишете не простой скриптик, а масштабную систему, которая в том числе использует BPF внутри. У меня даже есть пример такой системы на Go:

Проект Scope выглядит как один бинарник, который при запуске в инфраструктуре K8s или другого облака анализирует всё, что происходит вокруг, и показывает, какие есть контейнеры, сервисы, как они взаимодействуют и т. п. И многое из этого делается с использованием BPF. Интересный проект.
Анализируем программы на Go
Если помните, у нас был ещё один вопрос: можем ли мы анализировать программы, написанные на Go, с помощью BPF? Первая мысль — конечно! Какая разница, на каком языке написана программа? Ведь это просто скомпилированный код, который так же, как и все остальные программы, что-то считает на процессоре, кушает память как не в себя, взаимодействует с железом через ядро, а с ядром — через системные вызовы. В принципе, это правильно, но есть особенности разного уровня сложности.
Передача аргументов
Одна из особенностей состоит в том, что Go не использует ABI, который использует большинство остальных языков. Так уж получилось, что отцы-основатели решили взять ABI системы Plan 9, хорошо им знакомой.
ABI — это как API, соглашение о взаимодействии, только на уровне битов, байтов и машинного кода.
Основной элемент ABI, который нас интересует, — то, как в функцию передаются её аргументы и как из функции передаётся обратно ответ. Если в стандартном ABI x86-64 для передачи аргументов и ответа используются регистры процессора, то в Plan 9 ABI для этого использует стек.
Роб Пайк и его команда не планировали делать ещё один стандарт: у них уже был почти готовый компилятор для C для системы Plan 9, простой как дважды два, который они в кратчайшие сроки переделали в компилятор для Go. Инженерный подход в действии.
Но это, на самом деле, не слишком критичная проблема. Во-первых, мы, возможно, скоро увидим в Go передачу аргументов через регистры, а во-вторых, получать аргументы со стека из BPF несложно: в bpftrace уже добавили алиас sargX, а в BCC появится такой же, скорее всего, в ближайшее время.
Upd: с момента, когда я сделал доклад, появился даже подробный официальный proposal по переходу на использование регистров в ABI.
Уникальный идентификатор треда
Вторая особенность связана с любимой фичей Go — горутинами. Один из способов измерить latency функций — сохранить время вызова функции, засечь время выхода из функции и вычислить разницу; и сохранять время старта с ключом, в котором будет название функции и TID (номер треда). Номер треда нужен, так как одну и ту же функцию могут одновременно вызывать разные программы или разные потоки одной программы.

Но в Go горутины гуляют между системными тредами: сейчас горутина выполняется на одном треде, а чуть позже — на другом. И в случае с Go нам бы в ключ положить не TID, а GID, то есть ID горутины, но получить мы его не можем. Чисто технически этот ID существует. Грязными хаками его даже можно вытащить, так как он где-то в стеке, но делать это строго запрещено рекомендациями ключевой группы разработчиков Go. Они посчитали, что такая информация нам не нужна будет никогда. Как и Goroutine local storage, но это я отвлёкся.
Расширение стека
Третья проблема — самая серьёзная. Настолько серьёзная, что, даже если мы как-то решим вторую проблему, это нам никак не поможет измерять latency Go-функций.
Наверное, большинство читателей хорошо понимает, что такое стек. Тот самый стек, где в противоположность куче или хипу можно выделять память под переменные и не думать об их освобождении.
Если говорить о C, то стек там имеет фиксированный размер. Если мы вылезем за пределы этого фиксированного размера, то произойдёт знаменитый stack overflow.
В Go стек динамический. В старых версиях он представлял собой связанные куски памяти. Сейчас это непрерывный кусок динамического размера. Это значит, что, если выделенного куска нам не хватит, мы расширим текущий. А если расширить не сможем, то выделим другой большего размера и переместим все данные со старого места на новое. Это чертовски увлекательная история, которая затрагивает гарантии безопасности, cgo, сборщик мусора, но это уже тема для отдельной статьи.
Важно знать, что для того, чтобы Go мог сдвинуть стек, ему нужно пройтись по стеку вызовов программы, по всем указателям на стеке.
Тут и кроется основная проблема: uretprobes, которые используют для прикрепления BPF-функции, к моменту завершения выполнения функции динамически изменяют стек, чтобы встроить вызов своего обработчика, так называемого trampoline. И такое неожиданное для Go изменение его стека в большинстве случаев заканчивается падением программы. Упс!

Впрочем, эта история не уникальна. Разворачиватель «стека» C++ в момент обработки исключений тоже падает через раз.
Решения у данной проблемы нет. Как обычно в таких случаях, стороны перекидываются абсолютно обоснованными аргументами виновности друг друга.
Но если вам очень нужно поставить uretprobe, то проблему можно обойти. Как? Не ставить uretprobe. Можно поставить uprobe на все места, где мы выходим из функции. Таких мест может быть одно, а может быть 50.

И здесь уникальность Go играет нам на руку.
В обычном случае такой трюк не сработал бы. Достаточно умный компилятор умеет делать так называемый tail call optimization, когда вместо возврата из функции и возврата по стеку вызовов мы просто прыгаем в начало следующей функции. Такого рода оптимизация критически важна для функциональных языков вроде Haskell. Без неё они и шагу бы не могли ступить без stack overflow. Но с такой оптимизацией мы просто не сможем найти все места, где мы возвращаемся из функции.
Особенность в том, что компилятор Go версии 1.14 пока не умеет делать tail call optimization. А значит, трюк с прикреплением ко всем явным выходам из функции работает, хоть и очень утомителен.
Примеры
Не подумайте, что BPF бесполезен для Go. Это далеко не так: все остальное, что не задевает вышеуказанные нюансы, мы делать можем. И будем.
Давайте рассмотрим несколько примеров.
Для препарирования возьмём простенькую программку. По сути, это веб-сервер, который слушает на 8080 порту и имеет обработчик HTTP-запросов. Обработчик достанет из URL параметр name, параметр Go и сделает какую-то проверку «сайта», а затем все три переменные (имя, год и статус проверки) отправит в функцию prepareAnswer(), которая подготовит ответ в виде строки.

Проверка сайта — это HTTP-запрос, проверяющий, работает ли сайт конференции, с помощью канала и горутины. А функция подготовки ответа просто превращает всё это в читабельную строку.
Триггерить нашу программу будем простым запросом через curl:

В качестве первого примера с помощью bpftrace напечатаем все вызовы функций нашей программы. Мы здесь прикрепляемся ко всем функциям, которые попадают под main. В Go все ваши функции имеют символ, который выглядит как название пакета-точка-имя функции. Пакет у нас main, а рантайм функции был бы runtime.

Когда я делаю curl, то запускаются хендлер, функция проверки сайта и подфункция-горутина, а затем и функция подготовки ответа. Класс!
Дальше я хочу не только вывести, какие функции выполняются, но и их аргументы. Возьмём функцию prepareAnswer(). У неё три аргумента. Попробуем распечатать два инта.
Берём bpftrace, только теперь не однострочник, а скриптик. Прикрепляемся к нашей функции и используем алиасы для стековых аргументов, о которых я говорил.
В выводе мы видим то, что передали мы 2020, получили статус 200, и один раз передали 2021.

Но у функции три аргумента. Первый из них — строка. Что с ним?
Давайте просто выведем все стековые аргументы от 0 до 4. И что мы видим? Какая-то большая цифра, какая-то цифра поменьше и наши старые 2021 и 200. Что же это за странные цифры в начале?

Вот здесь уже полезно знать устройство Go. Если в C строка — это просто массив символов, который заканчивается нулём, то в Go строка — это на самом деле структура, состоящая из указателя на массив символов (кстати, не заканчивающийся нулём) и длины.

Но компилятор Go при передаче строчки в виде аргумента разворачивает эту структуру и передаёт её как два аргумента. И получается, что первая странная цифра — это как раз указатель на наш массив, а вторая — длина.
И правда: ожидаемая длина строки — 22.
Соответственно, немного фиксим наш скриптик, чтобы достать данные два значения через стек поинтер регистр и правильный оффсет, и с помощью встроенной функции str() выводим как строчку. Всё работает:

Ну и заглянем в рантайм. Например, мне захотелось узнать, какие горутины запускает наша программа. Я знаю, что горутины запускаются функциями newproc() и newproc1(). Подконнектимся к ним. Первым аргументом функции newproc1() является указатель на структуру funcval, которая имеет только одно поле — указатель на функцию:

В данном случае воспользуемся возможностью прямо в скрипте дефайнить структуры. Это чуть проще, чем играться с оффсетами. Вот мы вывели все горутины, которые запускаются при вызове нашего хендлера. И если после этого получить имена символов для наших оффсетов, то как раз среди них мы увидим нашу функцию checkSite. Ура!

Данные примеры — это капля в море возможностей BPF, BCC и bpftrace. При должном знании внутренностей и опыте можно достать почти любую информацию из работающей программы, не останавливая и не изменяя её.
Заключение
Это всё, о чём я хотел вам рассказать. Надеюсь, что у меня получилось вдохновить вас.
BPF — одно из самых модных и перспективных направлений в Linux. И я уверен, что в ближайшие годы мы увидим ещё очень и очень много интересного не только в самой технологии, но и в инструментах и её распространении.
Пока ещё не поздно и ещё не все знают о BPF, мотайте на ус, становитесь магами, решайте проблемы и помогайте своим коллегам. Говорят, что магические фокусы работают только один раз.
Что же до Go, то мы оказались, как обычно, довольно уникальными. Вечно у нас какие-то нюансы: то компилятор другой, то ABI, нужен какой-то GOPATH, имя, которое невозможно загуглить. Но мы стали силой, с которой принято считаться, и я верю, что жизнь станет только лучше.
Автор: Марко Кевац





")
{kind=link}