
Mikrotik QOS в распределенных системах или умные шейперы

А что бы вы со своей стороны могли предложить?
— Да что тут предлагать… А то пишут, пишут… конгресс, немцы какие-то… Голова пухнет. Взять все, да и поделить.
— Так я и думал, — воскликнул Филипп Филиппович, шлепнув ладонью по скатерти, — именно так и полагал.
М. Булгаков, «Собачье сердце»
Про разделение скорости, приоритезацию, работу шейпера и всего остального уже много всего написано и нарисовано. Есть множество статей, мануалов, схем и прочего, в том числе и написанных мной материалов. Но судя по возрастающим потокам писем и сообщений, пересматривая предыдущие материалы, я понял — что часть информации изложена не так подробно как это необходимо, другая часть просто морально устарела и просто путает новичков. На самом деле QOS на микротике не так сложен, как кажется, а кажется он сложным из-за большого количества взаимосвязанных нюансов. Кроме этого можно подчеркнуть, что крайне тяжело освоить данную тему руководствуясь только теорией, только практикой и только прочтением теории и примеров. Основным костылем в этом деле является отсутствие в Mikrotik визуального представления того, что происходит внутри очереди PCQ, а то, что нельзя увидеть и пощупать приходится вообразить. Но воображение у всех развито индивидуально в той или иной степени.
Поэтому я решил написать еще один материал, в котором я смешаю теорию с практикой, визуальными примерами и разобью данный материал на блоки от простого, к сложному. С каждым новым примером я буду добавлять необходимую информацию, и в самом конце вы получите полное представление, как это все работает. Думаю, так будет значительно проще понять основные принципы построения шейпера на микротике.
В данном материале я буду рассматривать только Queue Tree очереди с использованием PCQ. Уж извиняйте, Simple Queues для меня это — несколько не тот уровень возможностей. Так же не будет описан устаревший материал, который применим только для пятых версий ROS, хотя в некоторых моментах я буду на него ссылаться для сравнения.
Начнем с простого примера
Имеем микротик:
WAN интерфейс с белым адресом (1.1.1.1) и входящей скоростью 32 мегабита в секунду
LAN — c подсетью 192.168.0.0/24
Задача нарезать входящую в различных комбинациях (Download) скорость для подсети 192.168.0.0/24. Исходящую скорость (Upload) пока трогать не будем, но отмечу, что ее реализация почти ничем не отличается от реализации входящей скорости.
Для того чтобы что то нарезать на микротике мы должны определится с критериями отбора нужного нам трафика и выделить его. Для этого нам понадобится /ip firewall mangle.
Мангл можно представить в виде своеобразного фильтра, способного отбирать из общего потока пакеты и соединения по определенным критериям и выполнять с ними определенные действия.
Наш единственный критерий известен: нам из общего потока нужны только пакеты, которые идут в подсеть 192.168.0.0/24. В качестве действия с этими пакетами мы выберем — назначение пакету маркировки, впоследствии на основе этой маркировки пакеты можно будет обработать в Queue Tree.
Чтобы правильно промаркировать пакет — нужно знать по каким цепочкам в Mangle он проходит. Для этого нужно знать диаграммы движения пакетов (Packet Flow) причем не абы какие, а именно свежие диаграммы т.к. в шестой версии ROS схема немного изменилась. И естественно, посмотрев на эти диаграммы впервые, у вас на устах ничего кроме матерных слов не будет.

Опять же не все так сложно как кажется, данные диаграммы показывают, как ходит трафик во всех случаях, нам же для работы с шейпером понадобится лишь малая их часть.
Исходя из данной диаграммы, можно понять, что интересующий нас трафик идет по пути:
Input Interface > PREROUTING ->FORWARD ->POSTROUTING -> Output Interface
Схема при включенном NAT будет чуть пожирнее:
Input Interface > PREROUTING > DST-NAT >FORWARD > POSTROUTING > SRC-NAT > Output Interface
Какую из цепочек выбрать?
В пятых версиях ROS кроме того где находится NAT, нужно было еще знать где находится обработка очередей global-in, global-out и global-total.
В шестой версии стало все проще, т.к. вышеуказанные обработки упразднили и заменили одним global. И находится этот global в самом конце POSTROUTING, после него обрабатываются очереди SimleQueue и пакет отпускается на волю. Исходя из этого — нам неважно, где он теперь, т.к. все обработки по маркировке производятся до него.
А раз так, то единственное ограничение нам создает только NAT и выбор будет зависеть от направления трафика, который мы хотим промаркировать. По этому случаю накидал свою диаграмму:
{kind=link}

Как видно из диаграммы, для маркировки полученных пакетов, нам нужны цепочки, в которых доступны серые адреса подсети 192.168.0.0/24 (dst-address).
А видно их только в FORWARD и POSTROUTING.
Для того чтобы промаркировать Upload пакеты нужны цепочки со второй половины диаграммы, в которых доступны серые адреса подсети 192.168.0.0/24 (src-address).
А доступны они во всех трех цепочках PREROUTING, FORWARD, POSTROUTING.
Я рад, что не поленился и написал так много лишних букаф. И все для того, чтобы донести до вас информацию о том, что независимо от направления, которое мы хотим промаркировать, можно выбрать цепочку FORWARD в обоих случаях. Но так нельзя делать в пятых версиях ROS.
С цепочкой определились, теперь нужно определиться с тем, как мы будем помечать пакеты. Сначала пометить соединения, а уже потом в них пометить нужные пакеты? Или просто пометим пакеты и все взлетит?
Как то давно во времена первых версий из шестой линейки, мне написал один хороший человек (за что ему огромное спасибо!), и сказал, что у него в системе интересный глюк. Дал он мне соединение на TeamViewer и показал, как обычная маркировка пакетов помечает на треть (треть! Карл!) пакетов больше, чем маркировка при тех же параметрах но в пределах соединений. Соответственно и скорости в дереве были в норме, а вот на интерфейсах были на треть выше. Ковырялся долго, ничего не нашел. Делал повторую маркировку по тем же критериям вне коннекшена, предварительно отключив дальнейшие передачи уже помеченных пакетов в вышестоящих правилах. Все это с занесением в лог. Нормальные обычные пакеты, почему они не попали в коннекшен так и не понял.
Поставил ту же версию себе на тестовый стенд (один WAN, один LAN и все это под двойной NAT) настроил правила и поймал тот же глюк у себя. На протяжении четырех-пяти (уже не помню) версий я ловил данный глюк. Потом тупо сделал нагрузочный тест и понял — не такое уж и великое снижение нагрузки на камень, чтобы использовать маркировку в соединениях. С тех пор, на маркировку пакетов в соединениях — я забил. Как руки дойдут — проверю, а пока маркирую пакеты так.
Ну, с этим закончили. Правило в студию!
Данным правилом мы помечаем все пакеты, у которых dst-address равен адрес листу «LAN» ну и назначаем им packet-mark тоже «LAN»
/ip firewall mangle add action=mark-packet chain=forward comment=LAN disabled=no dst-address-list=LAN new-packet-mark=LAN passthrough=yes;
Так же добавим и сам адрес лист:
/ip firewall address-list add address=192.168.0.0/24 disabled=no list=LAN;
На этом маркировка в одном направлении закончена, чтобы промаркировать исходящий трафик, нам нужна копия правила, где dst-address-list=LAN заменен на src-address-list=LAN
Но как я уже писал, для примера мы возьмем только входящий трафик.
Ловим трафик в Queue Tree
Для того чтобы создать очередь PCQ в данном случае требуется одно правило и профиль в Queue Type. Но я создам два правила, чтобы на одном примере показать как в том, или ином случае ведет себя очередь при установке лимитов.
Родительская очередь
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=30M name=DOWNLOAD parent=global priority=8
Тут стоит прояснить несколько моментов:
parent=global — В данном параметре можно указать либо «global» либо имя интерфейса. Имя интерфейса тут играет роль определенного фильтра направления трафика и используется в сложных конфигурациях для исключения всех направлений кроме указанного интерфейса и действует только для этой очереди и ее потомков. Всегда указывайте в данном параметре «global» эффект будет тот же, а проблем меньше.
max-limit=30M — в условии задачи указано что канал у нас выдает 32 метра, но прописывать нужно чуть меньше доступной скорости. В противном случае вы упретесь в шейпер своего провайдера, ваш же просто не будет работать.
burst-limit=0 burst-threshold=0 burst-time=0s — отключены т.к. их использование мало чего дает при PCQ, но в профиле они имеют достаточную актуальность для использования.
priority=8 — приоритет очереди, 1 — высший приоритет, 8 — низший приоритет. НЕ РАБОТАЕТ если очередь имеет потомков.
Приоритеты работают только у потомков, причем конкурируют они друг с другом не только в пределах своего родителя, но и с потомками других родителей и только в случае общего дедушки, который лимитирует этим дармоедам скорость. При одинаковых приоритетах они распределят между собой всю доступную дедушкой скорость. При разных — сначала из общей дедушкиной миски едят высокоприоритетные, потом едят те у кого приоритет пониже и то только если что-то осталось, ну или родители развели дедушку на Limit-at. Хотя и родители могут устроить битву титанов среди своих потомков, если у них установлен не только Limit-at, но и Max-limit. Это будет в стиле: «не сжирайте все, у деда есть и другие дети с внуками от первого брака!»
Ну да постебались и хватит! Про лимиты и приоритеты расскажу более наглядно чуть позже.
В общем, мы создали родителя, теперь ему нужен потомок. Но для добавления потомка (конечной очереди) сначала необходимо добавить профиль. Добавляем.
/queue type add kind=pcq name= PCQ_DOWNLOAD_LAN pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
kind=pcq — Указываем что очередь которая использует данный профиль является инициатором подочередей PCQ
pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s — Настройки Burst Скоростей, об этом чуть позже.
pcq-classifier=dst-address — Данный параметр указывает по какому классификатору будут создаваться PCQ очереди. В данном случае по адресу назначения (входящий трафик)
pcq-dst-address-mask=32 и pcq-src-address-mask=32 — задают количество адресов в одной очереди. (32=одна очередь на один ip адрес)
pcq-rate=0 — Устанавливает верхний лимит скорости для одной PCQ очереди (в нашем случае для одного ip адреса) Если указан ноль — скорость не ограничена и будет разделена поровну между очередями (ip адресами). В нашем случае 30 мегабит будут разделены поровну между активными очередями (ip адресами).
pcq-limit=50 — лимит размера одной очереди (для одного ip адреса) Все данные в этой очереди при достижении лимитов задерживаются, все что в нее не влезло — уничтожается.
pcq-total-limit=2000 — лимит размера всех очередей.
Теперь, когда у нас есть родительская очередь и профиль под потомка, мы добавим самого потомка:
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=LAN packet-mark=LAN parent=DOWNLOAD priority=8 queue=PCQ_DOWNLOAD_LAN;
packet-mark=LAN — вот тут мы ловим в очередь поток промаркированных в мангле пакетов.
parent=DOWNLOAD — указали родителя, который ограничил нам скорость.
queue=PCQ_DOWNLOAD_LAN — ссылаемся на профиль с настройками в Queue Type
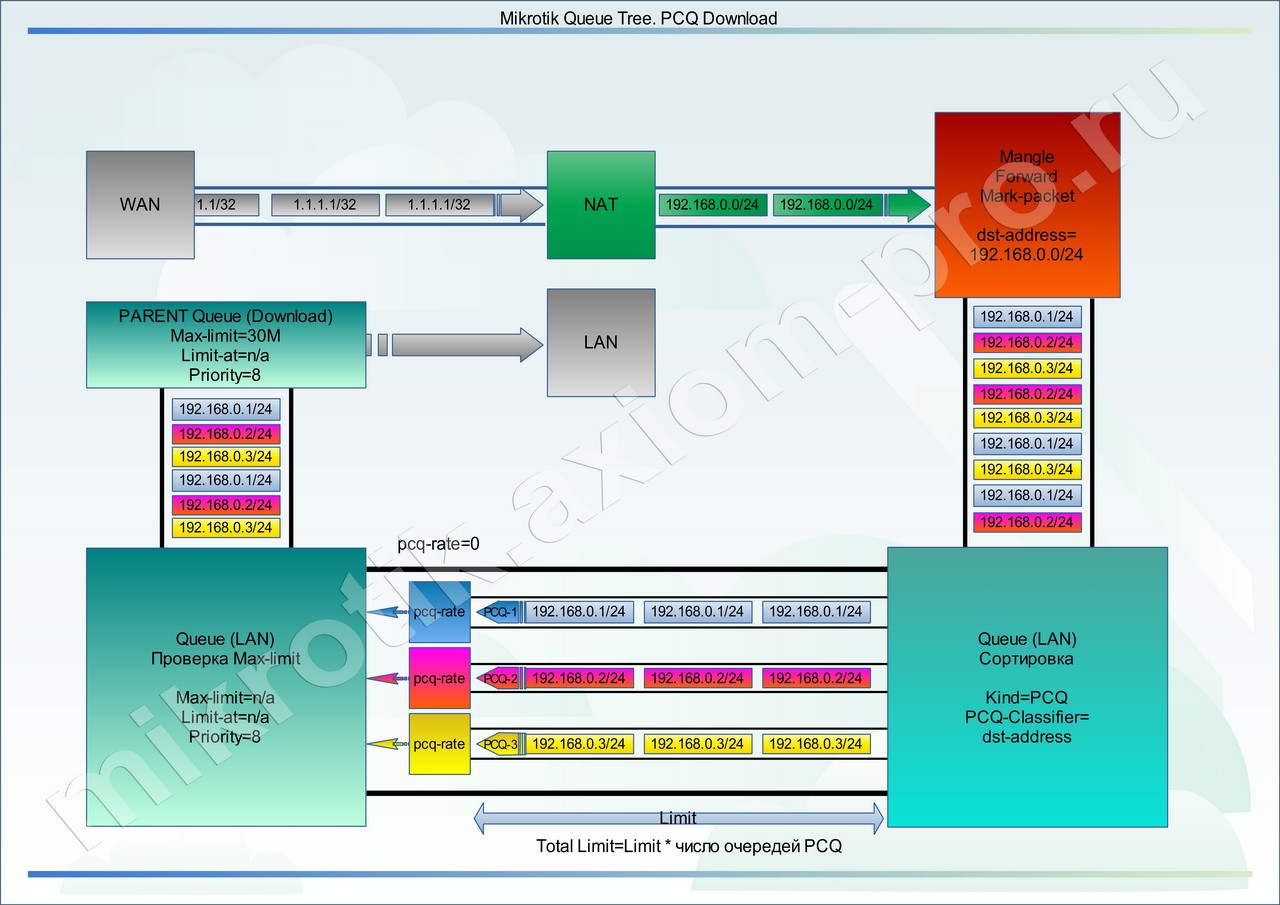
Ну, вот и закончили с правилами. Посмотрим на визуальную диаграмму.
Все что происходит наверху, вы уже знаете, далее смешанные промаркированные пакеты в хаотичном порядке, кучей подхватываются очередью потомком. И тут начинается самое интересное.
{kind=link}

Допустим, у нас сейчас в подсети работают три машины: 192.168.0.1, 192.168.0.2 и 192.168.0.3.
В связи с тем, что потомок привязан к профилю с именем «PCQ_DOWNLOAD_LAN», профиль ему сообщил: что нужно создать под каждый встреченный в промаркированном потоке dst-ip адрес отдельную PCQ очередь.
У нас внутри Queue Tree очереди будет создано три PCQ очереди (потока) с одинаковыми параметрами pcq-rate, pcq-limit и настройками Burst скоростей.
В данном случае очередь сработала как своеобразный сортировщик пакетов. И для каждого пользователя создала индивидуальную очередь.
Каждая очередь проходит через pcq-rate, именно эта штука и задерживает пакеты в индивидуальных очередях.
Далее пакеты смешиваются и поступают во вторую часть Queue Tree очереди c именем «LAN», где проходят проверку на суммарную скорость по Max-Limit, если он есть и исчерпан, то этот Max-limit будет поделен поровну между PCQ-очередями (потоками), задержка производится на уровне pcq-rate, какие-то очереди ускоряются, какие-то притормаживаются. Все что не влезло в pcq-limit — уничтожается.
Но у нас этого параметра в очереди «LAN» не установлено и поэтому трафик ползет вверх к родительской очереди (DOWNLOAD). Там все происходит по аналогии, проверяется Max-Limit и если он достигнут — родительская очередь пинает pcq-rate на закрытие дышла. Скорости потоков выравниваются, и все приходит в норму.
Представим на секунду, что мы не установили Max-Limit в родительской очереди. Так вот, если нигде по пути трафика при pcq-rate=0 не было обнаружено значения Max-Limit, то и вся очередь не будет работать, весь трафик пройдет сквозь шейпер без задержек, т.к. некому сообщить pcq-rate что канал не резиновый.
Многих мучает вопрос, если в данном случае pcq-rate=0, пользователей три, двое спят, а один качает. Он выжирает все 30 мегабит? — Да!
А что будет, если проснется еще один и тоже начнет качать? — Будет произведено перестроение и выравнивание скоростей. 30 мегабит они поделят поровну. Единственный нюанс — на это требуется время, второй пользователь будет немного медленнее набирать скорость, чем обычно.
Суть механизма заключается в задержке и уничтожении пакетов, которые не влезли в лимит. Протокол TCP устроен таким образом, что в рамках соединения — сервер который отправляет данные клиенту, проверяет как они дошли до него, если у пакетов выросла задержка или пакет потерялся (нарушение последовательности) сервер снижает скорость отправки чтобы увеличить стабильность.
pcq-limit и pcq-total-limit задаются экспериментально, чем больше лимит — тем больше задержка и больше занято оперативной памяти роутера. Чем меньше лимит — тем больше пакетов будет уничтожено.
Что будет, если задать pcq-rate=5M?
Каждый пользователь получит не более 5 мегабит. 3 активных пользователя * 5 мегабит =15 мегабит.
Три активных пользователя, все качают по полной, pcq-rate=11M?
Скорость упрется в Max-limit родительской очереди (30M) и данная скорость будет поделена между пользователями равномерно по 10 мегабит. Если один из них уйдет с закачки или снизит свою скорость минимум до 8 мегабит, двое остальных разгонятся до 11 мегабит.
Я очень надеюсь, что по данному примеру все понятно, если непонятно — прочтите еще раз и еще раз, далее будет сложнее.
Burst
Технология Burst предназначена для подачи увеличенной скорости при назначенном лимите на короткое время. Использовать данную функцию целесообразно на небольших по скорости тарифах, для ускорения веб-серфинга или быстрой подгрузки данных в приложения. Данная функция работает только в случае если pcq-rate не равен нулю.
Не буду до посинения грузить вас графиками и формулами расчета, лучше накидаю пример.
Pcq-rate=2M
pcq-burst-rate=4M
pcq-burst-threshold=1M
pcq-burst-time=10s
Максимальная скорость работы пользователя равна 2 мегабитам. Если скорость его работы в данный момент менее 1 мегабита (pcq-burst-threshold), ему станет доступна скорость в 4 мегабита (pcq-burst-rate) на 10 секунд (на практике меньше) это pcq-burst-time. Счетчик начинает тикать с того момента как будет превышен порог в 1 мегабит (pcq-burst-threshold), по истечении времени скорость упадет до pcq-rate, чтобы Burst снова стал доступен — скорость пользователя должна упасть ниже 1 мегабита и находится там не менее 10 секунд (pcq-burst-time)
Понятно, что это очень грубое объяснение, на самом деле время доступности burst рассчитывается по непростому алгоритму — время делится на 16 отрезков и учитывая почти все переменные скорости и лимитов рассчитывается время действия.
Данная функция потребляет значительное количество ресурсов, используйте ее с умом.
Для справки: При внесении любых изменений, в любую очередь и в любом ее проявлении (Tree или Simple) — все счетчики обнуляются в т.ч. и счетчики Burst. Если вы используете скрипты для автоматической коррекции значений Max-Limit типа QOSEvxController — будьте готовы отказаться от Burst или использовать циклы проверки очередей в QOSEvxController не так часто.
Ведро с болтами (Bucket)
Так же с недавнего времени в шестой версии ROS для очередей появился новый параметр bucket-size (размер ведра). Данный параметр может быть изменен в пределах от 0.1 до 10 и используется для задания емкости ведра с токенами. Емкость ведра рассчитывается по форумуле:
Емкость в МЕГАБАЙТАХ=bucket-size * max-limit
Над каждой очередью нависает ведро с гомном токенами, пока трафик в данной очереди не превышает лимит (max-limit) токены накапливаются в данном ведре. При переполнении ведра токен падающий в полное ведро уничтожается.
На что тратятся токены.
/queue tree add name=download parent=global packet-mark=PC1-traffic max-limit=10M bucket-size=10;
В данном примере, емкость ведра будет равна: (max-limit=10M) * (bucket-size=10) = 100 мегаБАЙТАМ
Если пользователь или пользователи потока пакетов с маркировкой «PC1-traffic» до недавнего времени ничего не качали на полной скорости — ведро с токенами в данной очереди будет полным, а это целых сто мегабайт трафика. И вот решили они дружно, что то качнуть, так вот, первых 100 мегабайт трафика они получат без ограничения скорости по max-limit, когда 100 мегабайт будет скачано очередь начнет ограничивать скорость согласно заданному max-limit=10M.
Кроме этого, если у очереди есть родитель с более жирным max-limit, то после того как потомок выжрет все свои токены, из своего ведра, он начнет забирать токены у родительской очереди.
Для чего это нужно?
Bucket-size это как своеобразный Burst, только не по скорости а по объему трафика. Применение его совместно с PCQ очередями даст лишь сомнительную пользу. В одиночных сеялках типа pfifo, red и sfq может быть крайне полезен. Для PCQ очередей — единственное, что приходит в голову, это то, что мы лимитируем родительскими очередями скорость, которая чуть ниже реальной скорости канала. Грамотное использование данной функции может кратковременно более полно эксплуатировать всю доступную скорость канала и сглаживать пики активности пользователей.
Более подробная диаграмма работы ведра:

Эквиваленты маркировки трафика
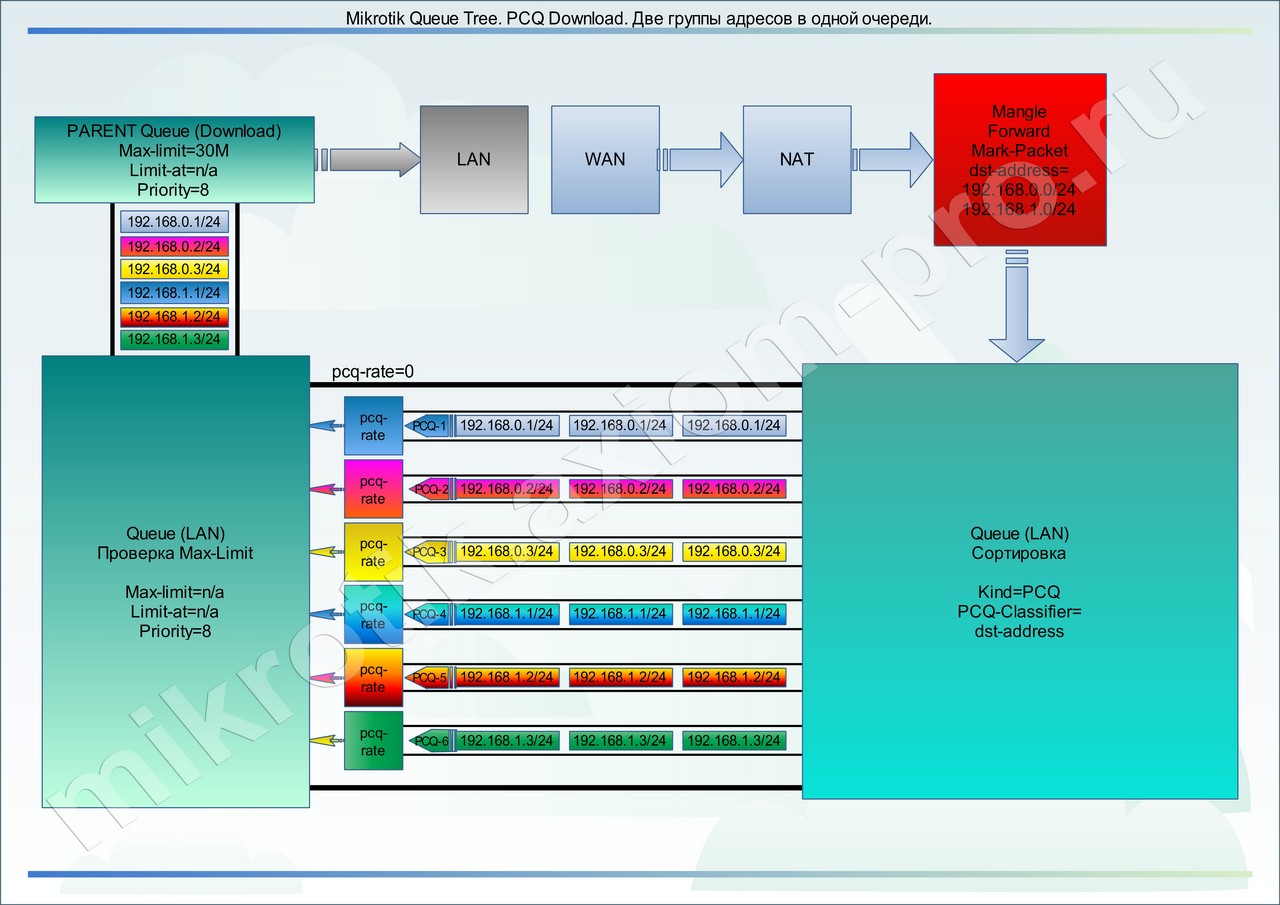
В данном примере я указал, что у нас одна подсеть (192.168.0.0/24) с тремя пользователями (192.168.0.1, 192.168.0.2, 192.168.0.3). Мы пометили трафик к данным адресам одним правилом в mangle и одним адрес-листом.
На всякий случай скажу, что для mangle нет разницы, как мы ему скормим адреса для пометки — обработаны они будут одинаково.
Подсеть целиком:
/ip firewall address-list add address=192.168.0.0/24 disabled=no list=LAN;
Диапазон адресов:
/ip firewall address-list add address=192.168.0.1-192.168.0.3 disabled=no list=LAN;
Отдельные адреса:
/ip firewall address-list add address=192.168.0.1 disabled=no list=LAN;
/ip firewall address-list add address=192.168.0.2 disabled=no list=LAN;
/ip firewall address-list add address=192.168.0.3 disabled=no list=LAN;
Аналогично обстоит дело и с PCQ очередями. PCQ очередь без проблем разбирает один поток пакетов, помеченный одним правилом, состоящий из адресов разных подсетей на подочереди.
Допустим, что мы подмешали еще трех пользователей из другой подсети (192.168.1.1, 192.168.1.2, 192.168.1.3). Просто добавив нужные записи в адрес-лист. Тогда получим такую картину:
{kind=link}

Исходя из всего вышеперечисленного, можно сделать вывод, что оперируем мы не подсетями, а группами ip адресов, которые создаем с помощью адрес-листов
В данном случае нет смысла раздельно маркировать трафик, делать два профиля и две очереди.
Такой подход необходим только в следующих случаях:
Когда требуется задать индивидуальный Max-Limit для выбранной группы адресов.
Когда требуется различный приоритет для групп адресов или типа трафика.
Когда требуется реализация различных тарифных планов для группы адресов. (pcq-rate)
И во всех возможных комбинациях вышеперечисленных случаев.
А вот пример того, как делать не надо:
{kind=link}

Полный листинг примера:
/ip firewall mangle add action=mark-packet chain=forward comment=LAN disabled=no dst-address-list=LAN new-packet-mark=LAN passthrough=yes;
/ip firewall address-list add address=192.168.0.0/24 disabled=no list=LAN;
/queue type add kind=pcq name= PCQ_DOWNLOAD_LAN pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=30M name=DOWNLOAD parent=global priority=8;
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=LAN packet-mark=LAN parent=DOWNLOAD priority=8 queue=PCQ_DOWNLOAD_LAN;
Пример второй. Приоритет одних, над другими.
Допустим, что мы администратор организации с небольшим количеством сотрудников.
Имеем исходные данные:
WAN интерфейс с белым адресом (1.1.1.1) и входящей скоростью 32 мегабита в секунду
LAN — c подсетью 192.168.0.0/24 (Рабочие станции Директоров)
LAN2 — c подсетью 192.168.1.0/24 (Рабочие станции Менеджеров)
В данном примере мы как раз, имеем один канал и две группы потребителей с разными приоритетами. Где директора имеют приоритет над менеджерами. Именно в этом случае для реализации данной схемы потребуется раздельная маркировка пакетов и раздельные очереди для групп пользователей.
Правила для маркировки:
/ip firewall mangle add action=mark-packet chain=forward comment=GROUP-A_DW disabled=no dst-address-list= GROUP-A new-packet-mark= GROUP-A_DW passthrough=yes;
/ip firewall mangle add action=mark-packet chain=forward comment=GROUP-B_DW disabled=no dst-address-list= GROUP-B new-packet-mark= GROUP-B_DW passthrough=yes;
Два правила для маркировки трафика с разными packet-mark и два списка для присвоения адресам принадлежности к группам.
/ip firewall address-list add address=192.168.0.0/24 disabled=no list=GROUP-A;
/ip firewall address-list add address=192.168.1.0/24 disabled=no list=GROUP-B;
Пришло время создать профили PCQ для очередей.
Сколько нужно профилей? По идее на загрузку хватит и одного профиля, но я всегда создаю по отдельному профилю на каждую группу и на каждое направление. Это позволяет иметь гибкие настройки на будущее, без дополнительного вмешательства в уже созданные правила и очереди
/queue type add kind=pcq name= GROUP-A_DW pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
/queue type add kind=pcq name= GROUP-B_DW pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=0 pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
Создаем дерево очередей:
Родительская очередь:
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=30M name=DOWNLOAD parent=global priority=8;
Потомки:
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name= GROUP-A_DW packet-mark= GROUP-A_DW parent=DOWNLOAD priority=7 queue= GROUP-A_DW;
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name= GROUP-B_DW packet-mark= GROUP-B_DW parent=DOWNLOAD priority=8 queue= GROUP-B_DW;
В данном примере нет ничего сложного, разница между очередями лишь в разных маркировках пакетов и разных приоритетах.
При низких скоростях данная схема будет прозрачно пропускать трафик через себя и любой из потребителей может получить все 30М указанных в родительской очереди.
При нехватке скорости в родительской очереди скорость начнет перераспределяться между потребителями по следующей схеме:
Группа с адресами GROUP-A_DW имеет более высокий приоритет (priority=7), ей будет отдана вся скорость родительской очереди (30M) и равномерно разделена между активными потребителями в пределах этой очереди.
Если данная группа не утилизировала весь доступный лимит скорости (30М), остатки этого лимита будут переданы в очередь с более низким приоритетом GROUP-B_DW (priority=8), где данные остатки будут равномерно разделены между активными потребителями в пределах этой очереди.
Если группа GROUP-A_DW утилизировала весь доступный лимит в 30 мегабит, группа GROUP-B_DW не получит вообще никакой скорости и никакой возможности передавать и получать пакеты из сети.
Для того чтобы группе с низким приоритетом оставалось хотя бы некоторое количество скорости, можно задать в очереди параметр limit-at=5M. Но данный параметр можно задать только совместно с параметром Max-Limit, ограничивать максимальную скорость группы нам не требуется — поэтому просто скопируем его из родительской очереди.
И вторая очередь после правок будет выглядеть так:
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=5M max-limit=30M name=GROUP-B_DW packet-mark=GROUP-B_DW parent=DOWNLOAD priority=8 queue=GROUP-B_DW;
В таком случае при нехватке скорости в родительской очереди, очередь с низким приоритетом будет всегда получать минимум 5 мегабит, которые сможет равномерно разделить между активными потребителями в пределах этой очереди.
Пример третий. Реализация тарифных планов с разделением на группы с разными приоритетами.
В данном примере будет рассмотрен своеобразный гибрид, который включает реализации из первых двух примеров.
Предположим, что мы субпровайдер с ограниченными финансовыми и техническими возможностями. У нас есть узкий канал в интернет, пара тарифных планов и две категории абонентов (физ.лица и юр.лица). Чаще всего, при предоставлении услуг юридическим лицам мы получаем от них большую выгоду, чем от физических лиц на тех же показателях скорости. Вместе с этим, мы предоставляем юридическим лицам некоторые дополнительные гарантии в виде гарантированной скорости и более оперативной технической поддержки.
Ну и как чаще всего бывает — мы немного увлеклись и подключили чуть больше абонентов, чем может вытянуть наш канал в интернет. По правильному — нужно расширить канал или подключить дополнительный с последующей балансировкой нагрузки. Но как уже было сказано, на это пока нет возможностей.
Но скорости в прайм-тайм не хватает, юридические лица начинают звонить и жаловаться на несоответствующую тарифному плану скорость, задержки пакетов, заикания телефонии и пр.
Частично облегчить данную ситуацию поможет шейпер с приоритетами как во втором примере, единственные отличия в том, что в данном примере скорость на одного абонента строго лимитирована и присутствует несколько тарифных планов.
Так же как и в предыдущих примерах, мы рассмотрим только входящую скорость. Однако во избежание путаницы в комментариях, именах маркировок и именах очередей будет присутствовать upload скорость.
Сокращения:
FIZ — физическое лицо.
UR — юридическое лицо.
1024K-1024K — Скорости по тарифу: Download-Upload
DW- Download
UL — Upload
Маркировка пакетов:
/ip firewall mangle add action=mark-packet chain=forward comment=FIZ_1024K-1024K_DW disabled=no dst-address-list= FIZ_1024K-1024K new-packet-mark= FIZ_1024K-1024K_DW passthrough=yes;
/ip firewall mangle add action=mark-packet chain=forward comment=FIZ_3072K-3072K_DW disabled=no dst-address-list= FIZ_3072K-3072K new-packet-mark= FIZ_3072K-3072K_DW passthrough=yes;
/ip firewall mangle add action=mark-packet chain=forward comment=UR_1024K-1024K_DW disabled=no dst-address-list= UR_1024K-1024K new-packet-mark= UR_1024K-1024K_DW passthrough=yes;
/ip firewall mangle add action=mark-packet chain=forward comment=UR_3072K-3072K_DW disabled=no dst-address-list= UR_3072K-3072K new-packet-mark= UR_3072K-3072K_DW passthrough=yes;
Четыре правила маркировки, которые выдадут нам четыре потока помеченных пакетов, рассортированных по четырем тарифным планам (Два для физ.лиц и два для юр.лиц.)
Чтобы привязать абонента к определенному тарифному плану, нужно поместить его ip адрес в нужный адрес-лист:
/ip firewall address-list add address=192.168.0.1 disabled=no list= FIZ_1024K-1024K;
/ip firewall address-list add address=192.168.0.2 disabled=no list= FIZ_3072K-3072K;
/ip firewall address-list add address=192.168.0.3 disabled=no list= FIZ_3072K-3072K;
/ip firewall address-list add address=192.168.0.4 disabled=no list= UR_3072K-3072K;
/ip firewall address-list add address=192.168.0.5 disabled=no list= UR_3072K-3072K;
И т.д.
Теперь необходимо добавить необходимые профили для очередей:
/queue type add kind=pcq name= FIZ_1024K-1024K_DW pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=1M pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
/queue type add kind=pcq name= FIZ_3072K-3072K_DW pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=3M pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
/queue type add kind=pcq name= UR_1024K-1024K_DW pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=1M pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
/queue type add kind=pcq name= UR_3072K-3072K_DW pcq-burst-rate=0 pcq-burst-threshold=0 pcq-burst-time=10s pcq-classifier=dst-address pcq-dst-address-mask=32 pcq-dst-address6-mask=64 pcq-limit=50 pcq-rate=3M pcq-src-address-mask=32 pcq-src-address6-mask=64 pcq-total-limit=2000;
Опять же я создал четыре профиля вместо двух, для сохранения гибкости настроек на будущее.
Далее построим дерево очередей:
Родительская очередь:
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=30M name=DOWNLOAD parent=global priority=8
Потомки:
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=FIZ_1024K-1024K_DW packet-mark=FIZ_1024K-1024K_DW parent=DOWNLOAD priority=8 queue= FIZ_1024K-1024K_DW;
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=FIZ_3072K-3072K_DW packet-mark=FIZ_3072K-3072K_DW parent=DOWNLOAD priority=8 queue= FIZ_3072K-3072K_DW;
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=UR_1024K-1024K_DW packet-mark=UR_1024K-1024K_DW parent=DOWNLOAD priority=7 queue= UR_1024K-1024K_DW;
/queue tree add burst-limit=0 burst-threshold=0 burst-time=0s disabled=no limit-at=0 max-limit=0 name=UR_3072K-3072K_DW packet-mark=UR_3072K-3072K_DW parent=DOWNLOAD priority=7 queue= UR_3072K-3072K_DW;
При реализации данного примера все будет работать следующим образом:
При низких скоростях абоненты без проблем получают свою тарифную скорость, которая ограничена параметром pcq-rate. Но самое интересное, начинается, когда активных абонентов больше чем может выдать канал.
Родительская очередь ограничена 30 мегабитами.
Тарифные планы физических лиц и сами физические лица между собой равноправны.
Тарифные планы юридических лиц и сами юридические лица тоже между собой равноправны.
Но в связи с тем, что очередь юридических лиц имеет более высокий приоритет, отсюда следует, что и сами юридические лица с их тарифными планами тоже имеют более высокий приоритет — и они будут обрабатываться первыми.
Вся доступная скорость отдается в тарифы для юридических лиц, каждый такой абонент ограничен скоростью тарифа заданной в параметре pcq-rate. Тем не менее, если данные абоненты интенсивно работают и их потребление трафика превышает в сумме 30 мегабит, то получим такую картину:
30 мегабит будут разделены поровну между юридическими лицами, на основании текущего количества пакетов в каждой PCQ очереди. На самом деле объяснить данную ситуацию не так просто, но я попробую.
Предположим, что у нас все перечисленные юридические лица качают «по полной». В данный момент есть четыре абонента с тарифом в 1 мегабит и двенадцать абонентов с тарифом в 3 мегабита.
4 * 1М = 4 мегабита
12 * 3M = 36 мегабит
4М + 36М = 40 мегабит требуется абонентам с одинаковым приоритетом.
Но у нас всего 30 мегабит. Все бы было просто в случае одинаковых тарифных планов: 30 мегабит поровну поделились бы между абонентами и все. Но как будет распределена скорость, если тарифы у нас разные в пределах одной приоритетной группы.
Как распределится недостаток скорости?
В голову приходит два варианта развития событий, но лишь один из них верный.
Недостаток скорости будет распределен в процентном соотношении исходя из скорости тарифного плана. Примерно как то так:
(100% / 40 мегабит которые требуются) = 2.5
30 мегабит которые есть * 2.5 = 75% от того что требуется мы имеем.
(1 мегабит / 100%) * 75% = 0.75 мегабита
(3 мегабита / 100%) * 75% = 2.25 мегабита
Проверяем:
4 абонента с тарифом в 1М (4 * 0.75) = 3 мегабита.
12 абонентов с тарифом в 3М (12 * 2.25) = 27 мегабит.
27+3 = 30 мегабит.
В принципе логично и относительно честно, только вот к сожалению данный сценарий будет обработан несколько иначе, а именно:
Вся доступная скорость (30 мегабит) будет распределятся равномерно, между участниками в равные единицы времени.
Представьте чан с 30 литрами воды, из которого отходят трубки одинакового сечения и N- количество стаканов разных размеров на столе, в которые одновременно разливают ограниченный объем воды одинаковыми струйками. В нашем примере самый маленький стакан имеет объем один литр, стакан побольше — три литра. (Три литра! Карл!) Как только мелкие стаканы будут наполнены — в них перестают лить воду. Вся оставшаяся вода будет продолжать разливаться в более крупные стаканы. Если и после этого вода в чане останется — она будет разлита в стаканы на другом низкоприоритетном столе. Но воды, то у нас не хватает даже на один стол.
Сложные вычисления:
Первый этап, первый временной промежуток:
4 стакана по литру = 4 литра
12 стаканов по три литра, но данном промежутке времени в них залит только литр = 12 литров.
30 литров — (4+12) =14 литров воды осталось в чане.
Второй этап, второй временной промежуток:
В связи с тем, что стаканов более трех литров в примере нет — просто разделим остатки воды между трехлитровыми стаканами.
14 литров / 12 стаканов= 1,1666666666666666666666666666667
Итог вычислений:
Пользователь на тарифе 1 мегабит получит весь мегабит целиком.
Пользователь на тарифе 3 мегабита получит 1+ 1,16 = 2,16 мегабита
Тоже самое если использовать простые вычисления:
(30 литров — 1 литр * 4) / 12 =2,16
Если внимательно посмотреть на оба примера (неправильный и верный) можно увидеть что в первом примере общая нехватка скорости по тарифу у всех ровно четверть от заявленной скорости и пострадали все тарифы одинаково. Во втором случае мелкие тарифные планы не почувствовали нехватки и получили заявленную скорость, однако тарифы с более высокой скоростью ощутили нехватку почти на треть.
Исходя из излишне-изложенной и не самой удачной метафоры, можно условно сказать, что тарифы с низкими скоростями имеют некий приоритет над тарифами с более высокими скоростями, при нехватке скорости, даже с одинаковым приоритетом.
Да это не совсем честно, но, к сожалению, данное поведение шейпера никак нельзя изменить.
Вот на этом моменте точка зрения господина Шарикова резко ушла в аут.
Страдать будут не все равномерно, а лишь те, кто имеет более веселый тарифный план. Ну и как водится чем больше скорость — тем больше платит абонент. Если данная ситуация еще более-менее допустима с физ.лицами, то с юр.лицами это даже досадным недоразумением назвать нельзя.
Ну да вернемся к дальнейшему обсуждению…
При данных условиях видно, что канала в 30 мегабит не хватает даже для обслуживания тарифных планов юридических лиц. Следовательно, пока юридические лица интенсивно получают данные, физические лица не получают вообще никакой скорости. Эту проблему можно решить заданием параметра limit-at, но в данном случае это еще сильнее снизит доступную скорость для юридических лиц.
Понятное дело, что подобная ситуация в реальности будет равна катастрофе. Но отодвинем катастрофу подальше и представим что юридических лиц не так много. А именно: 2 с тарифами в 1 мегабит и два с тарифами в 3 мегабита. И качают они «по полной».
Путем нехитрых вычислений (2*1 + 2*3 = 8, 30-8=22) понимаем, что после обслуживания юридических лиц, до очереди физических лиц дойдет всего 22 мегабита и разделятся они между ними согласно их тарифам. Если физических лиц слишком много и данной скорости на них не хватает — начнется дележка как в вышеописанном случае с большим количеством юридических лиц.
Но как бы, ни хватало скорости физическим лицам, юридические лица будут обслужены первыми.
Пример четвертый. Приоритет одного типа трафика над другим.
Дополнительно к классической системе приоритетов, когда поток разделен на несколько групп абонентов с разными приоритетами можно прикрутить дополнительные критерии разделения на приоритеты.
На эту тему можно спорить часами. Одни люди скажут, что при особых обстоятельствах, безусловно, стоит использовать приоритеты. И, конечно же, предоставят весомые аргументы в пользу данных решений. Другие начнут кричать про производительность и как бы этичность данного решения — мол, кто мы такие, чтобы решать за пользователя или абонента какой тип трафика ему важнее.
Я в этот дурацкий холивар никогда не влезал. Просто в виду большого опыта у меня своя точка зрения на этот счет. Все зависит от каждого конкретного случая и типа применения данной технологии.
Есть системы, в которых применение приоритетов только вредит общей работе — напрасно нагружает оборудование, следовательно, жрет электричество, мешает конечному пользователю самостоятельно определить какие либо проблемы с сетью (прим. — высокий приоритет icmp). Так же встречались системы на мыльницах с полностью загруженным маршрутизацией процессором, на который еще навешали приоритезацию и удивлялись, почему упала скорость.
Так же есть масса примеров, где данные решения нашли свое место и значительно улучшили работу сети и репутацию данных субпровайдеров. В некоторых случаях казалось, что применение приоритезации в каком-то конкретном случае было неоправданно (широкие каналы, всем всего хватает и данная фича просто нагружает процессор) тем не менее, при отвале сразу четырех аплинков из шести, скорости стало катастрофически не хватать. И эта якобы ненужная фича очень сильно снизила количество звонков в техническую поддержку. Да, существенно просела скорость загрузки торрентов тем не менее жалоб от «танкистов» на длинный пинг и лаги в игре не поступало.
Кроме всего этого, те люди у кого больше опыта знают, что под словом приоритезация понимается очень обширная тема и различные области применения. Думаю, что стоит перечислить основные типы:
Приоритезация по типу пользовательского трафика
Пользовательский поток делится на два, с разными приоритетами. Критериями разделения могут быть порты, протоколы, адреса назначения, адреса источники и целые подсети.
Производительность для высокого приоритета достигается за счет выделения дополнительной полосы скорости сверх тарифа абонента и более высокого приоритета очереди. Таким образом, абонент получает скорость тарифа под высокий приоритет + скорость тарифа под остальной трафик. По факту: абонент получает скорость тарифа умноженную на два. На практике, при свободном аплинке и полном использовании абонентом своей скорости по тарифу, абонент в среднем использует скорость тарифа+20%. При нехватке аплинка, низкоприоритетный трафик задерживается (полоса сужается), высокоприоритетный пропускается (отдельная полоса с более высоким приоритетом).
Приоритезация по направлению внешний <-> внутренний
Пользовательский поток делится на два, с разными приоритетами. Критериями разделения обычно служат подсети. В одном потоке идет внешний трафик в мир, во втором внутренний или межабонентский трафик. Используется крайне редко, обычно в распределенных системах, состоящих из нескольких маршрутизаторов.
Приоритезация по направлению внешнего трафика Download <-> Upload
Почти не используется в проводных сетях. Администраторы беспроводных сетей знают, что при односторонней передаче данных через радиооборудование (симплекс), скорость в разы выше чем при наличии встречного трафика (дуплекс). Чаще всего при наличии встречного трафика более 30% линк сильно деградирует
Для примера:
UDP тест на мостах UBNT через AirOS
симплекс ~130-160 мегабит/c.
Дуплекс ~40-50 мегабит/c.
В шестой версии ROS с ее изменениями (корневая очередь global и пометка в forward) появилась возможность контролировать дуплексный трафик с ограничением и снижением приоритета исходящего трафика от абонентов.
Данная теория в основном относится к B/G/N, при использовании оборудования работающего в AC режиме встречный трафик уже не так страшен.
Суровая практика
Ну, хорошо, теория и основы понятны. Стоит реальная задача сделать некий умный шейпер. С чего начать? Какие факторы нужно учесть, чтобы не собрать все грабли и впоследствии не переделывать все сначала?
Перед тем, как создать некоторую конструкцию шейпера необходимо в первую очередь определится с множеством параметров, которые имеет ваша сеть, или будет иметь в будущем. Если вы не сделаете этого сейчас, то в будущем могут возникнуть проблемы, которые заставят вас переделывать конструкцию с нуля. Так же стоит помнить, что каждая новая функция, требование или критерий будет стоить процессорного времени. Чаще всего эта стоимость будет возрастать в геометрической прогрессии. Поэтому дважды подумайте, на сколько критична и уместна данная функция в вашей конфигурации.
Первое с чего мы начинаем — это каналы в интернет.
Первое на что нужно обратить внимание — это число каналов. Если у вас несколько каналов в интернет или только планируется использовать несколько каналов в будущем, то, скорее всего, вам понадобится делать под каждый канал уникальный шейпер.
Сейчас объясню почему.
При создании общего шейпера, в кореневой очереди нужно будет прописать значение max-limit, которое будет равно сумме скоростей ваших каналов. В теории это будет работать, но на практике не все так сказочно как кажется.
Во первых, какой бы крутой у вас не стоял балансировщик нагрузки между каналами — всегда будет определенный дисбаланс. Разная нагрузка на каналы хотя бы в 1% нарушит стабильную работу шейпера и минимум 1 абонент на каждом канале будет недополучать тарифной скорости.
Во вторых, скорость некоторых каналов время от времени может «плыть» и в составе балансировки это приведет к краху т.к. ни балансировщик, ни шейпер не будут знать о реальных скоростях аплинков. И даже искусственно созданный запас по емкости в данном случае не спасет.
В третьих, при падении одного из каналов общая емкость изменится, и значение max-limit в очереди станет неактуальным. В результате этого шейпер будет прозрачно пропускать трафик, соблюдая лишь pcq-rate. Кто-то из абонентов будет получать полную скорость, а кто-то вообще ничего.
Исходя из вышеперечисленного — если у вас несколько каналов, считайте данный функционал обязательным, даже при условии что цена ему довольно высока.
А цена данного функционала — умножение нагрузки процессора от шейпера и числа его правил на количество обслуживаемых каналов.
Второе на что нужно обратить внимание — это гарантированная скорость каналов.
Если скорость на канале плавает в пределах более 20% это очень плохо. Выходов из данной ситуации несколько:
1. Использовать только гарантированные каналы. Это почти миф. Такие каналы предоставляют в основном юр.лицам со всеми вытекающими. Во вторых, если канал приходит в роутер по радио — толку от этого будет мало.
2. Использование не всей емкости канала. Достигается путем длительных тестов и вычисления его средней скорости. Думаю, что вас не сильно порадует фиксированное использование только половины потенциала канала. Зато стабильность значительно возрастет.
3. Использование коммерческих (QOSEvxController) или самописных скриптов для актуализации значения max-limit на канале. Данное решение чуть лучше второго варианта и позволяет получать с канала чуть больше его средней скорости.
Цена вопроса — Договор на юр.лицо или внешние скрипты и некоторые ресурсы процессора.
Третье и последнее по каналам — Тип подключения аплинков.
Да, я имею ввиду подключение по радио, со всеми вытекающими. При встречном трафике производительность данного канала снижается, и скорость значительно плывет. Решение тоже, что и выше, плюс добавление в конструкцию различных приоритетов для Download/Upload трафика. Данный функционал не добавляет существенной нагрузки на ЦП
Второе на что мы обратим внимание это число тарифных планов в сетке. Тут можно сказать одно — соблюдайте золотую середину. Не стоит прописывать только те тарифы которые у вас есть сейчас, сетку тарифных планов нужно продумать заранее т.к. значительно проще поднять их на этапе создания, чем добавлять их в будущем совершая ошибки и путаясь в тысячах правил mangle. Но также не увлекайтесь, каждый лишний тарифный план умножает нагрузку на процессор.
Третий вопрос для обсуждения — это: «Нужно ли выделять какому либо типу трафика более высокий приоритет?»
Безусловно, стоит хорошо задуматься о внедрении в конструкцию данного функционала. Разделение потока пакетов хотя бы на два приоритета приведет к увеличению нагрузки на процессор вдвое, а при использовании регулярных выражений хотя бы в одном правиле mangle в десятки раз.
Поэтому использовать данную фишку стоит только владельцам роутеров серии CCR, CHR, X86 с достаточным количеством свободных мегагерц на ядрах процессоров.
Однако полезность данной функции тоже очень положительно влияет на работу сети.
Во первых, многое зависит от того, кому вы предоставляете интернет.
Есть абоненты, которые с компьютером строго на «вы» и это самая болезненная для технической поддержки группа. Они собирают все тизеры на страницах интернета, соответственно на их компьютере просто зоопарк из вирусов, троянов и загрузчиков, да еще центр обновления у них сам качает, что захочет и когда захочет. А после школы возвращается их ребенок, запускает танки, ловит лаги и начинаются звонки в техническую поддержку. Вы вежливо объясняете, что у них проблемы с компьютером и чаще всего получаете ответ что им «все починили и настроили две недели назад» и что у них проблем быть не может. Ведь папины веселые картинки на весь экран, которые просили положить денег на какой-то номер телефона, удалил мамин знакомый программист с работы.
И чаще всего до таких абонентов трудно достучатся и найти нужные слова для убеждения. Увы, но это так!
При выделении в более высокий приоритет (отдельная полоса) к примеру, тех же танкистов, подобные проблемы переходят из разряда «острые» в разряд «вялотекущие». И очень часто со временем решаются сами собой (машина начинает тупить, Winlocker-ы портят папе настроение, шифровальщики добивают файлы) и это все как бы намекает, что специалиста все-таки придется пригласить для решения этих проблем.
Абоненты, которые с компьютером на «ты» обычно не звонят по пустякам в техподдержку, сначала проверяют свою машину, потом скорость, а потом уже набирают вас. И боже упаси вас, сказать им, что у них с машиной или сетевой картой, что-то не так, они вам горло перегрызут. Хотя в некоторых, из таких случаев провайдер действительно прав, т.к. человеческий фактор никто не отменял, мы все ошибаемся, забываем про роутер, про ноутбук который качает торренты на кухне и т.д.
Во втором случае, когда нас выручает приоритезация по типу трафика — это некоторые проблемы с нашим оборудованием или каналами в интернет. Когда суммарной полосы наших каналов существенно не хватает, низкоприоритетный трафик равноправных абонентов прижимается чтобы пропустить высокоприоритетный. Тут тот же бонус, геймеры а тем более танкисты в разгар игровых баталий — очень нервный народ и пока вы занимаетесь решением проблемы вам будет значительно легче пережить эту неисправность если в это время вам не так сильно будут обрывать телефон как при падении всех сервисов в целом.
Четвертый вопрос для обсуждения коснется только тех, у кого локальный трафик от абонентов превышает возможности внутренних линков до сегмента сети.
Наиболее остро вопрос стоит у тех субпровайдеров, кто раздает интернет по радио на распространенном оборудовании.
Для примера возьмем базовую станцию Ubiquiti Rocket M5 c хорошей панельной антенной, установленной по всем правилам и работающей на свободной частоте без помех.
К данной базе подключено максимальное число абонентов (30 устройств) и для чистоты теории они все находятся на одинаковом расстоянии и с одинаковыми сигналами.
И вот мы создали тепличные условия для красивой коробочки внутри которой китайское г…
Не скажу что у других производителей все супер внутри корпуса, но данный производитель очень тщательно скрывает очень важный параметр — пакетную производительность данного устройства.
По своему опыту скажу, что для данного устройства она лежит в пределах 16000-20000. Для Rocket M5 Titatium в районе 20000-25000.
И что это нам дает? При закачке торрентов скоростью 1 мегабит в секунду (не самые мелкие пакеты, если что) генерируется порядка 800-1100 пакетов в секунду.
Это говорит нам, что при самом плохом положении вещей максимальная производительность базы равна 15 мегабитам в секунду. А не 300 мегабит как пишут многие продаваны и не 150 как пишут более честные. А агрегация в суперфрейм тут пустой звук.
Но это самое плохое развитие событий, не все же абоненты качают только торренты, кто-то серфит, кто-то в скайпе сидит, кто-то фильм смотрит и т.д.
Количество пакетов снижается, но скорость растет. Так вот, средняя пропускная способность данной базовой станции в реальных условиях составляет порядка 35-45 мегабит. Ее максимум 70-80 мегабит на крупных пакетах при TCP трафике.
К чему я собственно веду: при 30 абонентах с тарифами в 5 мегабит, данная база не справится в глобальный прайм-тайм, который случается не так уж редко. (Выход ожидаемых фильмов, трансляции спортивных событий и пр.
Даже 20*5 это уже сто мегабит, понятное дело, что на базе есть свои очереди, таймслоты при использовании TDMA и прочее, база как бы обязана раздавать трафик честно и поровну. Но в реальных условиях, когда она явно перегружена по пакетам или радио, при наличии помех, разности расстояний и сигналов, равномерное деление по TDMA просто невозможно.
Если ближе к теме, назовем базовую станцию сегментом, т.к. у нормальных провайдеров сети сегментированы и броадкаст по ним без разрешения не гуляет.
И на каждый сегмент сделаем дополнительное разделение и ограничение скорости, чтобы в случае нехватки ресурсов базы скорость делилась бы равномерно между теми, кому она нужна.
Легко сказать, но очень дорого сделать. Ведь каждый сегмент (VLAN).
Будет умножать нагрузку от шейпера на количество введенных в шейпер сегментов.
Данный функционал, несомненно, нужен беспроводным субпровайдерам, но он приводит к огромному количеству правил и гигантской трате системных ресурсов.
Но его все, же используют, просто данный функционал легко настраивается на терминирующем роутере, из двух роутеров получается распределенная система.
Первый роутер следит за скоростями каналов в интернет, приоритезацией и нарезкой скоростей. Далее трафик проходит во второй роутер, на котором шейпер следит за нагрузкой на сегменты сети. А так же за межабонентским трафиком, о котором я и расскажу.
Последний вопрос: «Зачем нужен межабонентский трафик и как больно грабли ударят по лбу?»
Межабонентский трафик нужен в первую очередь для снижения нагрузки на интернет каналы.
В сети может быть поднят локальный ретрекер, либо другие различные сервисы, либо совсем без них.
Суть заключается в том, чтобы при закачке какого либо торрента, торрент-клиент обращался в первую очередь к другим абонентам и в случае наличия у них запрашиваемых частей или файлов целиком получал их внутри сети на максимальной скорости.
Так же возможна реализация внутренних серверов и сервисов самим провайдером.
Ну, тут я уже предвижу: «Да кому нужны ваши внутренние серваки и ретрекеры? Тут у каждого второго оптика»
У меня есть клиент, официальный провайдер. У него три канала по 4 мегабита от спутниковых модемов и около 400 абонентов. В радиусе 700км нет ни оптики, ни кабеля, ни файфая, ни жопорезов с 3-4g. В общем, ничего нет. Пинг 700мс. А вы тут как сырки в масле, с оптикой и 21 веком. Еще будут вопросы, зачем субпровайдерам кеширующие прокси, ретрекеры и прочие примочки?
Так что межабонентскому трафику быть!
Как бы это хорошо не звучало, это единственная вещь, которую ROS шестой версии не в силах победить. Связано это с тем, что при замене global-in, global-out и global-total которые были в пятой версии, на global который теперь есть в шестой, пропала возможность дважды помечать трафик и дважды прогонять его через HTB.
Проблема в том, что мы физически не сможем пометить трафик от одного абонента до другого в пределах одного сегмента (базы), т.к. для одного абонента пакет будет помечен как исходящий, а для второго он является входящим. Для mangle это пакет соответствующий критериям двух правил, сначала он получит одну метку, а потом будет переразмечен другим правилом. И все бы получилось, если бы между маркировками можно было бы принудительно отправить пакет в обработку очередей. Но чудес не бывает.
Кто-то скажет или спросит: «В пятой же версии все получится?» Да, конечно. Проверял, работает на ура! Только вот пятая версия имеет свои минусы и уже не подходит под те задачи, которые требуются от этого роутера.
Как же быть? Есть некоторые варианты решения подобной задачи, трафик будет зарегистрирован лишь в одном направлении и с более низким приоритетом, интернет трафик будет иметь более высокий приоритет. Кроме этого данный поток полезно лимитировать. Схема довольно сложная и создается под отдельно взятые конфигурации. Если кто-то из специалистов сейчас прочитал это и понял, о чем я говорю — свяжитесь со мной, возможно, вместе мы придумаем что-то более продвинутое.
Кроме всего этого межабонентский трафик нельзя маркировать на одном роутере с контролем нагрузки на интернет аплинки. Даже если вы решили рискнуть производительностью роутера и сделать комбаин «все в одном» (Контроль нагрузки на каналы+нарезка скорости по тарифам+приоритеты+контроль внутренних сегментов+маркировка межабонентского трафика) то вы через некоторое время заметите, что в корневых очередях каналов в интернет регистрируется нагрузка, которой на самом деле не существует. Это межабонентский трафик маркируется, попадает в очередь, передается в корневую очередь сегмента, а оттуда попадает в очередь канала.
Изменение родителя у очереди канала или сегмента не даст никакого положительного результата. По факту получится, что канал свободен, но шейпер будет думать, что нагрузка на нем есть. Решение данной проблемы — распределенная система.
Ну, вот как бы и решилось что к чему, естественно если есть биллинг, то он должен поддерживать работу с адрес-листами для сообщения микротику какому ip адресу и сколько скорости выдать. Тоже самое относится к скрипту балансировки, он должен сообщать своими списками какой ip адрес, к какому каналу привязан в данный момент времени. Кроме этого если вы создаете распределенную систему на двух роутерах, вам потребуется синхронизация адрес листов между роутерами, реализовать ее можно написав скрипт, либо внешний обработчик на api. Так же в скором времени такой скрипт можно будет приобрести (EvxListSync).
Практическая и заключительная часть:
Думаю что после того как мы определились с необходимыми параметрами, следует приступить от слов к делу. В данном примере я опишу основную конструкцию, в которую можно добавить некоторый функционал по своему вкусу или удалить лишний.
Предположим, что у нас есть два канала в интернет и балансировщик, который раскидывает абонентов по каналам и формирует динамически нужные адрес листы ISP1 и ISP2.
Для каждого канала будет создан индивидуальный шейпер.
В примере будут рассмотрены четыре тарифных плана, два для физ.лиц и два для юр.лиц.
Если есть биллинг — он должен добавлять ip адреса пользователей в соответствующие списки для привязки абонента к нужному тарифному плану. Если биллинга нет — заполнять данные адрес листы потребуется вручную.
Кроме всего этого мы разделим трафик по типу на два приоритета.
Разметка
Маркируем весь входящий трафик к адресам из списка «SHAPER_TARGET» назначая пакетам метку «CLASS-B-DL»
/ip firewall mangle add action=mark-packet chain=forward comment=CLASS-B-DL dst-address-list=SHAPER_TARGET new-packet-mark=CLASS-B-DL;
Далее отлавливаем пакеты с меткой «CLASS-B-DL» и переразмечаем их, назначая метку более приоритетного класса. В более выскокий приоритет попадут: ICMP, DNS, SSH, TELNET, RDP и пакеты у которых в качестве адреса источника указан любой адрес из списка CLASS-A-SITES.
/ip firewall mangle add action=mark-packet chain=forward comment=CLASS-A-ICMP-DL new-packet-mark=CLASS-A-DL packet-mark=CLASS-B-DL protocol=icmp;
/ip firewall mangle add action=mark-packet chain=forward comment=CLASS-A-DNS_TCP-DL dst-port=53 new-packet-mark=CLASS-A-DL packet-mark=CLASS-B-DL protocol=tcp;
/ip firewall mangle add action=mark-packet chain=forward comment=CLASS-A-DNS_UDP-DL dst-port=53 new-packet-mark=CLASS-A-DL packet-mark=CLASS-B-DL protocol=udp;
/ip firewall mangle add action=mark-packet chain=forward comment=CLASS-A-SSH-DL dst-port=22 new-packet-mark=CLASS-A-DL packet-mark=CLASS-B-DL protocol=tcp;
/ip firewall mangle add action=mark-packet chain=forward comment=CLASS-A-TELNET-DL dst-port=23 new-packet-mark=CLASS-A-DL packet-mark=CLASS-B-DL protocol=tcp;
/ip firewall mangle add action=mark-packet chain=forward comment=CLASS-A-RDP-DL dst-port=3389 new-packet-mark=CLASS-A-DL packet-mark=CLASS-B-DL protocol=tcp;
/ip firewall mangle add action=mark-packet chain=forward comment=CLASS-A-SITES-DL new-packet-mark=CLASS-A-DL packet-mark=CLASS-B-DL src-address-list=CLASS-A-SITES;
Выполняем аналогичную процедуру для исходящего трафика:
/ip firewall mangle add action=mark-packet chain= forward comment=CLASS-B-UL new-packet-mark=CLASS-B-UL src-address-list=SHAPER_TARGET;
/ip firewall mangle add action=mark-packet chain= forward comment=CLASS-A-ICMP-UL new-packet-mark=CLASS-A-UL packet-mark=CLASS-B-UL protocol=icmp;
/ip firewall mangle add action=mark-packet chain= forward comment=CLASS-A-DNS_TCP-UL new-packet-mark=CLASS-A-UL packet-mark=CLASS-B-UL protocol=tcp src-port=53;
/ip firewall mangle add action=mark-packet chain= forward comment=CLASS-A-DNS_UDP-UL new-packet-mark=CLASS-A-UL packet-mark=CLASS-B-UL protocol=udp src-port=53;
/ip firewall mangle add action=mark-packet chain= forward comment=CLASS-A-SSH-UP new-packet-mark=CLASS-A-UL packet-mark=CLASS-B-UL protocol=tcp src-port=22;
/ip firewall mangle add action=mark-packet chain= forward comment=CLASS-A-TELNET-UL new-packet-mark=CLASS-A-UL packet-mark=CLASS-B-UL protocol=tcp src-port=23;
/ip firewall mangle add action=mark-packet chain= forward comment=CLASS-A-RDP-UL new-packet-mark=CLASS-A-UL packet-mark=CLASS-B-UL protocol=tcp src-port=3389;
/ip firewall mangle add action=mark-packet chain= forward comment=CLASS-A-SITES-UL new-packet-mark=CLASS-A-UL packet-mark=CLASS-B-UL src-address-list=CLASS-A-SITES;
После этих действий мы получаем четыре потока промаркированных пакетов:
CLASS-A-DL
CLASS-B-DL
CLASS-A-UL
CLASS-B-UL
Ищем в данных потоках пакеты принадлежащие абонентам, которые в данный момент работают на первом канале и переразмечаем их:
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1-CLASS-A-DL dst-address-list=ISP1 new-packet-mark=ISP1-CLASS-A-DL packet-mark=CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1-CLASS-B-DL dst-address-list=ISP1 new-packet-mark=ISP1-CLASS-B-DL packet-mark=CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1-CLASS-A-UL dst-address-list=ISP1 new-packet-mark=ISP1-CLASS-A-UL packet-mark=CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1-CLASS-B-UL dst-address-list=ISP1 new-packet-mark=ISP1-CLASS-B-UL packet-mark=CLASS-B-UL;
После переразметки получим еще четыре дополнительных потока:
ISP1-CLASS-A-DL
ISP1-CLASS-B-DL
ISP1-CLASS-A-UL
ISP1-CLASS-B-UL
Теперь нужно разобрать эти четыре потока на тарифные планы:
Адрес лист «1024-1024-8» в формате «Входящая скорость-Исходящая скорость-Приоритет». Приоритет равен 8 если физ.лицо и 7 если юр.лицо. Так удобнее управлять листами из биллинга.
Выделяем четыре потока для тарифного плана «1024-1024-8» два под загрузку, два под отдачу:
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_1024-1024-8_CLASS-A_DL dst-address-list=1024-1024-8 new-packet-mark=ISP1_1024-1024-8_CLASS-A_DL packet-mark=ISP1-CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_1024-1024-8_CLASS-B_DL dst-address-list=1024-1024-8 new-packet-mark=ISP1_1024-1024-8_CLASS-B_DL packet-mark=ISP1-CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_1024-1024-8_CLASS-A_UL dst-address-list=1024-1024-8 new-packet-mark=ISP1_1024-1024-8_CLASS-A_UL packet-mark=ISP1-CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_1024-1024-8_CLASS-B_UL dst-address-list=1024-1024-8 new-packet-mark=ISP1_1024-1024-8_CLASS-B_UL packet-mark=ISP1-CLASS-B-UL;
Повторяем действия для трех оставшихся тарифных планов:
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_2048-2048-8_CLASS-A_DL dst-address-list=2048-2048-8 new-packet-mark=ISP1_2048-2048-8_CLASS-A_DL packet-mark=ISP1-CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_2048-2048-8_CLASS-B_DL dst-address-list=2048-2048-8 new-packet-mark=ISP1_2048-2048-8_CLASS-B_DL packet-mark=ISP1-CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_2048-2048-8_CLASS-A_UL dst-address-list=2048-2048-8 new-packet-mark=ISP1_2048-2048-8_CLASS-A_UL packet-mark=ISP1-CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_2048-2048-8_CLASS-B_UL dst-address-list=2048-2048-8 new-packet-mark=ISP1_2048-2048-8_CLASS-B_UL packet-mark=ISP1-CLASS-B-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_1024-1024-7_CLASS-A_DL dst-address-list=1024-1024-7 new-packet-mark=ISP1_1024-1024-7_CLASS-A_DL packet-mark=ISP1-CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_1024-1024-7_CLASS-B_DL dst-address-list=1024-1024-7 new-packet-mark=ISP1_1024-1024-7_CLASS-B_DL packet-mark=ISP1-CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_1024-1024-7_CLASS-A_UL dst-address-list=1024-1024-7 new-packet-mark=ISP1_1024-1024-7_CLASS-A_UL packet-mark=ISP1-CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_1024-1024-7_CLASS-B_UL dst-address-list=1024-1024-7 new-packet-mark=ISP1_1024-1024-7_CLASS-B_UL packet-mark=ISP1-CLASS-B-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_2048-2048-7_CLASS-A_DL dst-address-list=2048-2048-7 new-packet-mark=ISP1_2048-2048-7_CLASS-A_DL packet-mark=ISP1-CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_2048-2048-7_CLASS-B_DL dst-address-list=2048-2048-7 new-packet-mark=ISP1_2048-2048-7_CLASS-B_DL packet-mark=ISP1-CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_2048-2048-7_CLASS-A_UL dst-address-list=2048-2048-7 new-packet-mark=ISP1_2048-2048-7_CLASS-A_UL packet-mark=ISP1-CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP1_2048-2048-7_CLASS-B_UL dst-address-list=2048-2048-7 new-packet-mark=ISP1_2048-2048-7_CLASS-B_UL packet-mark=ISP1-CLASS-B-UL;
После данных действий мы получили 16 потоков промаркированных пакетов.
Потоки канала:
ISP1-CLASS-A-DL
ISP1-CLASS-B-DL
ISP1-CLASS-A-UL
ISP1-CLASS-B-UL
Потеряли актуальность т.к. все пакеты с данными маркировками были переразмечены.
Но общие потоки:
ISP1-CLASS-A-DL
ISP1-CLASS-B-DL
ISP1-CLASS-A-UL
ISP1-CLASS-B-UL
еще содержат пакеты других каналов, в нашем случае: канала ISP2.
Далее нужно произвести переразметку для второго канала, аналогично первому:
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2-CLASS-A-DL dst-address-list=ISP2 new-packet-mark=ISP2-CLASS-A-DL packet-mark=CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2-CLASS-B-DL dst-address-list=ISP2 new-packet-mark=ISP2-CLASS-B-DL packet-mark=CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2-CLASS-A-UL dst-address-list=ISP2 new-packet-mark=ISP2-CLASS-A-UL packet-mark=CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2-CLASS-B-UL dst-address-list=ISP2 new-packet-mark=ISP2-CLASS-B-UL packet-mark=CLASS-B-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_1024-1024-8_CLASS-A_DL dst-address-list=1024-1024-8 new-packet-mark=ISP2_1024-1024-8_CLASS-A_DL packet-mark=ISP2-CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_1024-1024-8_CLASS-B_DL dst-address-list=1024-1024-8 new-packet-mark=ISP2_1024-1024-8_CLASS-B_DL packet-mark=ISP2-CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_1024-1024-8_CLASS-A_UL dst-address-list=1024-1024-8 new-packet-mark=ISP2_1024-1024-8_CLASS-A_UL packet-mark=ISP2-CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_1024-1024-8_CLASS-B_UL dst-address-list=1024-1024-8 new-packet-mark=ISP2_1024-1024-8_CLASS-B_UL packet-mark=ISP2-CLASS-B-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_2048-2048-8_CLASS-A_DL dst-address-list=2048-2048-8 new-packet-mark=ISP2_2048-2048-8_CLASS-A_DL packet-mark=ISP2-CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_2048-2048-8_CLASS-B_DL dst-address-list=2048-2048-8 new-packet-mark=ISP2_2048-2048-8_CLASS-B_DL packet-mark=ISP2-CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_2048-2048-8_CLASS-A_UL dst-address-list=2048-2048-8 new-packet-mark=ISP2_2048-2048-8_CLASS-A_UL packet-mark=ISP2-CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_2048-2048-8_CLASS-B_UL dst-address-list=2048-2048-8 new-packet-mark=ISP2_2048-2048-8_CLASS-B_UL packet-mark=ISP2-CLASS-B-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_1024-1024-7_CLASS-A_DL dst-address-list=1024-1024-7 new-packet-mark=ISP2_1024-1024-7_CLASS-A_DL packet-mark=ISP2-CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_1024-1024-7_CLASS-B_DL dst-address-list=1024-1024-7 new-packet-mark=ISP2_1024-1024-7_CLASS-B_DL packet-mark=ISP2-CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_1024-1024-7_CLASS-A_UL dst-address-list=1024-1024-7 new-packet-mark=ISP2_1024-1024-7_CLASS-A_UL packet-mark=ISP2-CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_1024-1024-7_CLASS-B_UL dst-address-list=1024-1024-7 new-packet-mark=ISP2_1024-1024-7_CLASS-B_UL packet-mark=ISP2-CLASS-B-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_2048-2048-7_CLASS-A_DL dst-address-list=2048-2048-7 new-packet-mark=ISP2_2048-2048-7_CLASS-A_DL packet-mark=ISP2-CLASS-A-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_2048-2048-7_CLASS-B_DL dst-address-list=2048-2048-7 new-packet-mark=ISP2_2048-2048-7_CLASS-B_DL packet-mark=ISP2-CLASS-B-DL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_2048-2048-7_CLASS-A_UL dst-address-list=2048-2048-7 new-packet-mark=ISP2_2048-2048-7_CLASS-A_UL packet-mark=ISP2-CLASS-A-UL;
/ip firewall mangle add action=mark-packet chain=forward comment=ISP2_2048-2048-7_CLASS-B_UL dst-address-list=2048-2048-7 new-packet-mark=ISP2_2048-2048-7_CLASS-B_UL packet-mark=ISP2-CLASS-B-UL;
Получаем еще 16 потоков для второго канала.
Итого у нас 32 потока, общие потоки классов и потоки каналов стали неактуальны т.к. все пакеты в них были переразмечены и образовали новые 32 потока.
На этом маркировка закончена.
Профили
Перед тем как начинать работу с деревом необходимо создать профили очередей их число не влияет на производительность, число профилей обычно соответствует числу тарифных планов, но для гибкости я делаю по отдельному профилю на загрузку/отдачу.
/queue type add kind=pcq name=DL-1024-1024-8 pcq-classifier=dst-address pcq-dst-address6-mask=64 pcq-rate=1M pcq-src-address6-mask=64 pcq-burst-rate=2M pcq-burst-threshold=1200K pcq-burst-time=15s;
/queue type add kind=pcq name=UL-1024-1024-8 pcq-classifier=src-address pcq-dst-address6-mask=64 pcq-rate=1M pcq-src-address6-mask=64 pcq-burst-rate=2M pcq-burst-threshold=1200K pcq-burst-time=15s;
/queue type add kind=pcq name=DL-2048-2048-8 pcq-classifier=dst-address pcq-dst-address6-mask=64 pcq-rate=2M pcq-src-address6-mask=64 pcq-burst-rate=4M pcq-burst-threshold=2500K pcq-burst-time=15s;
/queue type add kind=pcq name=UL-2048-2048-8 pcq-classifier=src-address pcq-dst-address6-mask=64 pcq-rate=2M pcq-src-address6-mask=64 pcq-burst-rate=4M pcq-burst-threshold=2500K pcq-burst-time=15s;
/queue type add kind=pcq name=DL-1024-1024-7 pcq-classifier=dst-address pcq-dst-address6-mask=64 pcq-rate=1M pcq-src-address6-mask=64 pcq-burst-rate=2M pcq-burst-threshold=1200K pcq-burst-time=15s;
/queue type add kind=pcq name=UL-1024-1024-7 pcq-classifier=src-address pcq-dst-address6-mask=64 pcq-rate=1M pcq-src-address6-mask=64 pcq-burst-rate=2M pcq-burst-threshold=1200K pcq-burst-time=15s;
/queue type add kind=pcq name=DL-2048-2048-7 pcq-classifier=dst-address pcq-dst-address6-mask=64 pcq-rate=2M pcq-src-address6-mask=64 pcq-burst-rate=4M pcq-burst-threshold=2500K pcq-burst-time=15s;
/queue type add kind=pcq name=UL-2048-2048-7 pcq-classifier=src-address pcq-dst-address6-mask=64 pcq-rate=2M pcq-src-address6-mask=64 pcq-burst-rate=4M pcq-burst-threshold=2500K pcq-burst-time=15s;
После того как профили созданы, можно приступать к созданию дерева.
Дерево
Ранее я упоминал о проблемах, которые возникнут при получении интернет каналов по радио, так же вполне вероятно, что провайдер вам выдаст не симметричный канал, либо вы будете использовать adsl или 3-4g.
Исходя из этого, сразу закладываем в конструкцию: родительскую дуплексную очередь и подочереди для симплекса.
Родительская очередь для первого канала:
/queue tree add name=ISP1-Duplex parent=global queue=default;
Подочереди для симплекса:
/queue tree add name=DL-ISP1 parent=ISP1-Duplex queue=default;
/queue tree add name=UL-ISP1 parent=ISP1-Duplex queue=default;
После этого можем добавлять конечных потомков, в этих очередях и будут заданы приоритеты.
Тарифный план 1024-1024 для физ.лиц на два приоритета+приоритет входящего трафика:
/queue tree add name=DL-ISP1_1024-1024-8_CLASS-A packet-mark=ISP1_1024-1024-8_CLASS-A_DL parent=DL-ISP1 priority=5 queue=DL-1024-1024-8;
/queue tree add name=DL-ISP1_1024-1024-8_CLASS-B packet-mark=ISP1_1024-1024-8_CLASS-B_DL parent=DL-ISP1 priority=6 queue=DL-1024-1024-8;
/queue tree add name=UL-ISP1_1024-1024-8_CLASS-A packet-mark=ISP1_1024-1024-8_CLASS-A_UL parent=UL-ISP1 priority=7 queue=UL-1024-1024-8;
/queue tree add name=UL-ISP1_1024-1024-8_CLASS-B packet-mark=ISP1_1024-1024-8_CLASS-B_UL parent=UL-ISP1 priority=8 queue=UL-1024-1024-8;
Остальные три тарифных плана:
/queue tree add name=DL-ISP1_2048-2048-8_CLASS-A packet-mark=ISP1_2048-2048-8_CLASS-A_DL parent=DL-ISP1 priority=5 queue=DL-2048-2048-8;
/queue tree add name=DL-ISP1_2048-2048-8_CLASS-B packet-mark=ISP1_2048-2048-8_CLASS-B_DL parent=DL-ISP1 priority=6 queue=DL-2048-2048-8;
/queue tree add name=UL-ISP1_2048-2048-8_CLASS-A packet-mark=ISP1_2048-2048-8_CLASS-A_UL parent=UL-ISP1 priority=7 queue=UL-2048-2048-8;
/queue tree add name=UL-ISP1_2048-2048-8_CLASS-B packet-mark=ISP1_2048-2048-8_CLASS-B_UL parent=UL-ISP1 priority=8 queue=UL-2048-2048-8;
/queue tree add name=DL-ISP1_1024-1024-7_CLASS-A packet-mark=ISP1_1024-1024-7_CLASS-A_DL parent=DL-ISP1 priority=3 queue=DL-1024-1024-7;
/queue tree add name=DL-ISP1_1024-1024-7_CLASS-B packet-mark=ISP1_1024-1024-7_CLASS-B_DL parent=DL-ISP1 priority=4 queue=DL-1024-1024-7;
/queue tree add name=UL-ISP1_1024-1024-7_CLASS-A packet-mark=ISP1_1024-1024-7_CLASS-A_UL parent=UL-ISP1 priority=5 queue=UL-1024-1024-7;
/queue tree add name=UL-ISP1_1024-1024-7_CLASS-B packet-mark=ISP1_1024-1024-7_CLASS-B_UL parent=UL-ISP1 priority=6 queue=UL-1024-1024-7;
/queue tree add name=DL-ISP1_2048-2048-7_CLASS-A packet-mark=ISP1_2048-2048-7_CLASS-A_DL parent=DL-ISP1 priority=3 queue=DL-2048-2048-7;
/queue tree add name=DL-ISP1_2048-2048-7_CLASS-B packet-mark=ISP1_2048-2048-7_CLASS-B_DL parent=DL-ISP1 priority=4 queue=DL-2048-2048-7;
/queue tree add name=UL-ISP1_2048-2048-7_CLASS-A packet-mark=ISP1_2048-2048-7_CLASS-A_UL parent=UL-ISP1 priority=5 queue=UL-2048-2048-7;
/queue tree add name=UL-ISP1_2048-2048-7_CLASS-B packet-mark=ISP1_2048-2048-7_CLASS-B_UL parent=UL-ISP1 priority=6 queue=UL-2048-2048-7;
С первым каналом закончили, добавляем очереди второго канала по аналогии с первым:
/queue tree add name=ISP2-Duplex parent=global queue=default;
/queue tree add name=DL-ISP2 parent=ISP2-Duplex queue=default;
/queue tree add name=UL-ISP2 parent=ISP2-Duplex queue=default;
/queue tree add name=DL-ISP2_1024-1024-8_CLASS-A packet-mark=ISP2_1024-1024-8_CLASS-A_DL parent=DL-ISP2 priority=5 queue=DL-1024-1024-8;
/queue tree add name=DL-ISP2_1024-1024-8_CLASS-B packet-mark=ISP2_1024-1024-8_CLASS-B_DL parent=DL-ISP2 priority=6 queue=DL-1024-1024-8;
/queue tree add name=UL-ISP2_1024-1024-8_CLASS-A packet-mark=ISP2_1024-1024-8_CLASS-A_UL parent=UL-ISP2 priority=7 queue=UL-1024-1024-8;
/queue tree add name=UL-ISP2_1024-1024-8_CLASS-B packet-mark=ISP2_1024-1024-8_CLASS-B_UL parent=UL-ISP2 priority=8 queue=UL-1024-1024-8;
/queue tree add name=DL-ISP2_2048-2048-8_CLASS-A packet-mark=ISP2_2048-2048-8_CLASS-A_DL parent=DL-ISP2 priority=5 queue=DL-2048-2048-8;
/queue tree add name=DL-ISP2_2048-2048-8_CLASS-B packet-mark=ISP2_2048-2048-8_CLASS-B_DL parent=DL-ISP2 priority=6 queue=DL-2048-2048-8;
/queue tree add name=UL-ISP2_2048-2048-8_CLASS-A packet-mark=ISP2_2048-2048-8_CLASS-A_UL parent=UL-ISP2 priority=7 queue=UL-2048-2048-8;
/queue tree add name=UL-ISP2_2048-2048-8_CLASS-B packet-mark=ISP2_2048-2048-8_CLASS-B_UL parent=UL-ISP2 priority=8 queue=UL-2048-2048-8;
/queue tree add name=DL-ISP2_1024-1024-7_CLASS-A packet-mark=ISP2_1024-1024-7_CLASS-A_DL parent=DL-ISP2 priority=3 queue=DL-1024-1024-7;
/queue tree add name=DL-ISP2_1024-1024-7_CLASS-B packet-mark=ISP2_1024-1024-7_CLASS-B_DL parent=DL-ISP2 priority=4 queue=DL-1024-1024-7;
/queue tree add name=UL-ISP2_1024-1024-7_CLASS-A packet-mark=ISP2_1024-1024-7_CLASS-A_UL parent=UL-ISP2 priority=5 queue=UL-1024-1024-7;
/queue tree add name=UL-ISP2_1024-1024-7_CLASS-B packet-mark=ISP2_1024-1024-7_CLASS-B_UL parent=UL-ISP2 priority=6 queue=UL-1024-1024-7;
/queue tree add name=DL-ISP2_2048-2048-7_CLASS-A packet-mark=ISP2_2048-2048-7_CLASS-A_DL parent=DL-ISP2 priority=3 queue=DL-2048-2048-7;
/queue tree add name=DL-ISP2_2048-2048-7_CLASS-B packet-mark=ISP2_2048-2048-7_CLASS-B_DL parent=DL-ISP2 priority=4 queue=DL-2048-2048-7;
/queue tree add name=UL-ISP2_2048-2048-7_CLASS-A packet-mark=ISP2_2048-2048-7_CLASS-A_UL parent=UL-ISP2 priority=5 queue=UL-2048-2048-7;
/queue tree add name=UL-ISP2_2048-2048-7_CLASS-B packet-mark=ISP2_2048-2048-7_CLASS-B_UL parent=UL-ISP2 priority=6 queue=UL-2048-2048-7;
После этого нужно внести в адрес лист «SHAPER_TARGET» диапазоны подсетей с абонентами, проследить, что биллинг добавляет адреса абонентов в нужные списки, проверить вносит ли балансировщик адреса абонентов в списки каналов.
Так же требуется задать значения max-limit в корневых очередях, эти значения должны быть на 5-20% ниже реальной скорости, которую вам выдает провайдер.
Итого получилось:
52 правила в Mangle, 8 профилей, 38 очередей
Но если приблизится к более реальным условиям, получаются огромные числа.
Возьмем для примера 5 каналов и 12 тарифных планов.
16 правил в Mangle для определения типов трафика.
5 каналов * 4 правила для разделения = 20 правил в Mangle
5 каналов * (4 правила на тариф* 12 тарифов)=240 правил в Mangle
Итого правил в mangle = 276 (260 зависят от числа тарифов и каналов)
Профили
12*2=24
Дерево
5 каналов на 3 корневые очереди =15 очередей
5 каналов * (4 очереди на тариф * 12 тарифов) = 240 очередей
Итого: 255 очередей
И данные цифры вполне нормально уживутся на CCR, CHR, X86 если не баловаться с регулярными выражениями. Если хочется добавить еще одну ступень для определения типа трафика — умножайте число очередей и правил на два.
Для тех, кто вопреки убеждениям хочет прикрутить к данной схеме еще и контроль внутренних сегментов сети на этом же роутере — число правил и очередей умножайте на число сегментов и к полученному значению прибавляйте количество сегментов умноженное на два.
В данном примере, при десяти сегментах количество правил в mangle станет около 2610, а количество очередей примерно 2580.
К тому же если в сети будет присутствовать межабонентский трафик — по лбу очень больно ударят грабли, о которых я писал ранее.
Для этих целей нужен второй шейпер на втором промежуточном роутере, кроме того что это все можно относительно просто реализовать, второй роутер дает еще много полезных преимуществ.
Тем более владельцам гипервизоров поднятие второго экземпляра ничего не стоит.
Думаю, что теперь многим станет понятно, почему на SOHO мыльницах с 680 мегагерцами на борту можно реализовать только простую сеялку на две группы пользователей и не более.
Ну, раз уж я начал говорить про второй роутер и про контроль сегментов, грех будет не рассказать, как это все делается.
Распределенный шейпер
Первым делом нужно разметить трафик на втором роутере.
Маркируем внешний входящий трафик, назначая метку: «EXT_CLASS-B_DL»
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B_DL disabled=no src-address-list=!SHAPER_TARGET dst-address-list=SHAPER_TARGET new-packet-mark=EXT_CLASS-B_DL passthrough=yes;
Далее отлавливаем пакеты с меткой «EXT_CLASS-B_DL» и переразмечаем их, назначая метку более приоритетного класса. Делаем по аналогии как на первом роутере.
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-ICMP-DL new-packet-mark=EXT_CLASS-A_DL packet-mark=EXT_CLASS-B_DL protocol=icmp;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-DNS_TCP-DL dst-port=53 new-packet-mark=EXT_CLASS-A_DL packet-mark=EXT_CLASS-B_DL protocol=tcp;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-DNS_UDP-DL dst-port=53 new-packet-mark=EXT_CLASS-A_DL packet-mark=EXT_CLASS-B_DL protocol=udp;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-SSH-DL dst-port=22 new-packet-mark=EXT_CLASS-A_DL packet-mark=EXT_CLASS-B_DL protocol=tcp;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-TELNET-DL dst-port=23 new-packet-mark=EXT_CLASS-A_DL packet-mark=EXT_CLASS-B_DL protocol=tcp;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-RDP-DL dst-port=3389 new-packet-mark=EXT_CLASS-A_DL packet-mark=EXT_CLASS-B_DL protocol=tcp;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-SITES-DL new-packet-mark=EXT_CLASS-A_DL packet-mark=EXT_CLASS-B_DL src-address-list=CLASS-A-SITES;
После этого мы получили два потока промаркированных пакетов внешнего входящего трафика:
EXT_CLASS-A_DL
EXT_CLASS-B_DL
Далее нам нужно их преобразовать в четыре потока, два потока для физ.лиц и два для юр.лиц, делать мы это будем перемаркировкой согласно адрес листам тарифных планов.
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-FL_DL new-packet-mark=EXT_CLASS-A-FL_DL packet-mark=EXT_CLASS-A_DL dst-address-list=1024-1024-8;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B-FL_DL new-packet-mark=EXT_CLASS-B-FL_DL packet-mark=EXT_CLASS-B_DL dst-address-list=1024-1024-8;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-FL_DL new-packet-mark=EXT_CLASS-A-FL_DL packet-mark=EXT_CLASS-A_DL dst-address-list=2048-2048-8;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B-FL_DL new-packet-mark=EXT_CLASS-B-FL_DL packet-mark=EXT_CLASS-B_DL dst-address-list=2048-2048-8;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-UR_DL new-packet-mark=EXT_CLASS-A-UR_DL packet-mark=EXT_CLASS-A_DL dst-address-list=1024-1024-7;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B-UR_DL new-packet-mark=EXT_CLASS-B-UR_DL packet-mark=EXT_CLASS-B_DL dst-address-list=1024-1024-7;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-UR_DL new-packet-mark=EXT_CLASS-A-UR_DL packet-mark=EXT_CLASS-A_DL dst-address-list=2048-2048-7;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B-UR_DL new-packet-mark=EXT_CLASS-B-UR_DL packet-mark=EXT_CLASS-B_DL dst-address-list=2048-2048-7;
Теперь у нас есть в распоряжении четыре потока:
EXT_CLASS-A-FL_DL
EXT_CLASS-B-FL_DL
EXT_CLASS-A-UR_DL
EXT_CLASS-B-UR_DL
Аналогичную процедуру производим с исходящим наружу трафиком:
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B_UL disabled=no src-address-list=SHAPER_TARGET dst-address-list=!SHAPER_TARGET new-packet-mark=EXT_CLASS-B_UL passthrough=yes;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-ICMP_UL new-packet-mark=EXT_CLASS-A_UL packet-mark=EXT_CLASS-B_UL protocol=icmp;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-DNS_TCP_UL new-packet-mark=EXT_CLASS-A_UL packet-mark=EXT_CLASS-B_UL protocol=tcp src-port=53;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-DNS_UDP_UL new-packet-mark=EXT_CLASS-A_UL packet-mark=EXT_CLASS-B_UL protocol=udp src-port=53;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-SSH_UP new-packet-mark=EXT_CLASS-A_UL packet-mark=EXT_CLASS-B_UL protocol=tcp src-port=22;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-TELNET_UL new-packet-mark=EXT_CLASS-A_UL packet-mark=EXT_CLASS-B_UL protocol=tcp src-port=23;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-RDP_UL new-packet-mark=EXT_CLASS-A_UL packet-mark=EXT_CLASS-B_UL protocol=tcp src-port=3389;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-SITES_UL new-packet-mark=EXT_CLASS-A_UL packet-mark=EXT_CLASS-B_UL src-address-list=CLASS-A-SITES;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-FL_UL new-packet-mark=EXT_CLASS-A-FL_UL packet-mark=EXT_CLASS-A_UL src-address-list=1024-1024-8;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B-FL_UL new-packet-mark=EXT_CLASS-B-FL_UL packet-mark=EXT_CLASS-B_UL src-address-list=1024-1024-8;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-FL_UL new-packet-mark=EXT_CLASS-A-FL_UL packet-mark=EXT_CLASS-A_UL src-address-list=2048-2048-8;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B-FL_UL new-packet-mark=EXT_CLASS-B-FL_UL packet-mark=EXT_CLASS-B_UL src-address-list=2048-2048-8;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-UR_UL new-packet-mark=EXT_CLASS-A-UR_UL packet-mark=EXT_CLASS-A_UL src-address-list=1024-1024-7;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B-UR_UL new-packet-mark=EXT_CLASS-B-UR_UL packet-mark=EXT_CLASS-B_UL src-address-list=1024-1024-7;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-A-UR_UL new-packet-mark=EXT_CLASS-A-UR_UL packet-mark=EXT_CLASS-A_UL src-address-list=2048-2048-7;
/ip firewall mangle add action=mark-packet chain=forward comment=EXT_CLASS-B-UR_UL new-packet-mark=EXT_CLASS-B-UR_UL packet-mark=EXT_CLASS-B_UL src-address-list=2048-2048-7;
После того как мы добавили правила для маркировки исходящего трафика получаем уже восемь потоков:
EXT_CLASS-A-FL_DL
EXT_CLASS-B-FL_DL
EXT_CLASS-A-UR_DL
EXT_CLASS-B-UR_DL
EXT_CLASS-A-FL_UL
EXT_CLASS-B-FL_UL
EXT_CLASS-A-UR_UL
EXT_CLASS-B-UR_UL
Для обработки межабонентского трафика так же потребуется добавить еще один поток, но на данном этапе в нем будет сразу два направления т.к. для одного абонента трафик является входящим, а для другого исходящим.
/ip firewall mangle add action=mark-packet chain=forward comment=INT disabled=no src-address-list=SHAPER_TARGET dst-address-list=SHAPER_TARGET new-packet-mark=INT passthrough=yes;
Теперь мы дошли до финальной стадии маркировки. С помощью разделенных адрес листов сегментов, мы сможем определить, откуда и куда идут пакеты. В данном примере у нас всего два сегмента VID30 и VID40.
Входящий трафик:
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_EXT_CLASS-A-FL_DL dst-address-list=VID30 new-packet-mark=VID30_EXT_CLASS-A-FL_DL packet-mark=EXT_CLASS-A-FL_DL;
/ip firewall mangle add action=mark-packet chain=forward comment= VID30_EXT_CLASS-B-FL_DL dst-address-list=VID30 new-packet-mark= VID30_EXT_CLASS-B-FL_DL packet-mark=EXT_CLASS-B-FL_DL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_EXT_CLASS-A-UR_DL dst-address-list=VID30 new-packet-mark=VID30_EXT_CLASS-A-UR_DL packet-mark=EXT_CLASS-A-UR_DL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_EXT_CLASS-B-UR_DL dst-address-list=VID30 new-packet-mark=VID30_EXT_CLASS-B-UR_DL packet-mark=EXT_CLASS-B-UR_DL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_INT_DL dst-address-list=VID30 new-packet-mark=VID30_INT_DL packet-mark=INT;
Исходящий трафик, по аналогии:
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_EXT_CLASS-A-FL_UL src-address-list=VID30 new-packet-mark=VID30_EXT_CLASS-A-FL_UL packet-mark=EXT_CLASS-A-FL_UL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_EXT_CLASS-B-FL_UL src-address-list=VID30 new-packet-mark=VID30_EXT_CLASS-B-FL_UL packet-mark=EXT_CLASS-B-FL_UL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_EXT_CLASS-A-UR_UL src-address-list=VID30 new-packet-mark=VID30_EXT_CLASS-A-UR_UL packet-mark=EXT_CLASS-A-UR_UL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_EXT_CLASS-B-UR_UL src-address-list=VID30 new-packet-mark=VID30_EXT_CLASS-B-UR_UL packet-mark=EXT_CLASS-B-UR_UL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID30_INT_UL src-address-list=VID30 new-packet-mark=VID30_INT_UL packet-mark=INT;
Повторяем то же самое для второго сегмента:
Входящий трафик:
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_EXT_CLASS-A-FL_DL dst-address-list=VID40 new-packet-mark=VID40_EXT_CLASS-A-FL_DL packet-mark=EXT_CLASS-A-FL_DL;
/ip firewall mangle add action=mark-packet chain=forward comment= VID40_EXT_CLASS-B-FL_DL dst-address-list=VID40 new-packet-mark= VID40_EXT_CLASS-B-FL_DL packet-mark=EXT_CLASS-B-FL_DL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_EXT_CLASS-A-UR_DL dst-address-list=VID40 new-packet-mark=VID40_EXT_CLASS-A-UR_DL packet-mark=EXT_CLASS-A-UR_DL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_EXT_CLASS-B-UR_DL dst-address-list=VID40 new-packet-mark=VID40_EXT_CLASS-B-UR_DL packet-mark=EXT_CLASS-B-UR_DL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_INT_DL dst-address-list=VID40 new-packet-mark=VID40_INT_DL packet-mark=INT;
Исходящий трафик:
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_EXT_CLASS-A-FL_UL src-address-list=VID40 new-packet-mark=VID40_EXT_CLASS-A-FL_UL packet-mark=EXT_CLASS-A-FL_UL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_EXT_CLASS-B-FL_UL src-address-list=VID40 new-packet-mark=VID40_EXT_CLASS-B-FL_UL packet-mark=EXT_CLASS-B-FL_UL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_EXT_CLASS-A-UR_UL src-address-list=VID40 new-packet-mark=VID40_EXT_CLASS-A-UR_UL packet-mark=EXT_CLASS-A-UR_UL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_EXT_CLASS-B-UR_UL src-address-list=VID40 new-packet-mark=VID40_EXT_CLASS-B-UR_UL packet-mark=EXT_CLASS-B-UR_UL;
/ip firewall mangle add action=mark-packet chain=forward comment=VID40_INT_UL src-address-list=VID40 new-packet-mark=VID40_INT_UL packet-mark=INT;
На этом маркировка завершена.
Профили
Тут ничего особенного, два профиля по дефолту
/queue type add kind=pcq name=PCQ-DL pcq-classifier=dst-address pcq-dst-address6-mask=64 pcq-rate=0 pcq-src-address6-mask=64;
/queue type add kind=pcq name=PCQ-UL pcq-classifier=src-address pcq-dst-address6-mask=64 pcq-rate=0 pcq-src-address6-mask=64;
Дерево
Корневая очередь, в которой можно задать max-limit (скорость соединения с первым роутером)
/queue tree add name=ISP parent=global queue=default max-limit=900M;
Дуплексная подочередь на сегмент сети:
/queue tree add name=DUPLEX-VID30 parent=ISP queue=default max-limit=40M;
Симплекс сегмента на загрузку:
/queue tree add name=DL_VID30 parent=DUPLEX-VID30 queue=default;
Очереди потомки:
/queue tree add name=DL_VID30_EXT_CLASS-A-FL_DL packet-mark=VID30_EXT_CLASS-A-FL_DL parent=DL_VID30 priority=5 queue=PCQ-DL;
/queue tree add name=DL_VID30_EXT_CLASS-B-FL_DL packet-mark=VID30_EXT_CLASS-B-FL_DL parent=DL_VID30 priority=6 queue=PCQ-DL;
/queue tree add name=DL_VID30_EXT_CLASS-A-UR_DL packet-mark=VID30_EXT_CLASS-A-UR_DL parent=DL_VID30 priority=4 queue=PCQ-DL;
/queue tree add name=DL_VID30_EXT_CLASS-B-UR_DL packet-mark=VID30_EXT_CLASS-B-UR_DL parent=DL_VID30 priority=5 queue=PCQ-DL;
/queue tree add name=DL_VID30_INT_DL packet-mark=VID30_INT_DL parent=DL_VID30 priority=7 queue=PCQ-DL max-limit=20M;
Почти, то же самое для исходящего трафика:
Симплекс сегмента на отдачу:
/queue tree add name=UL_VID30 parent=DUPLEX-VID30 queue=default;
Очереди потомки:
/queue tree add name=UL_VID30_EXT_CLASS-A-FL_UL packet-mark=VID30_EXT_CLASS-A-FL_UL parent=UL_VID30 priority=6 queue=PCQ-UL;
/queue tree add name=UL_VID30_EXT_CLASS-B-FL_UL packet-mark=VID30_EXT_CLASS-B-FL_UL parent=UL_VID30 priority=7 queue=PCQ-UL;
/queue tree add name=UL_VID30_EXT_CLASS-A-UR_UL packet-mark=VID30_EXT_CLASS-A-UR_UL parent=UL_VID30 priority=5 queue=PCQ-UL;
/queue tree add name=UL_VID30_EXT_CLASS-B-UR_UL packet-mark=VID30_EXT_CLASS-B-UR_UL parent=UL_VID30 priority=6 queue=PCQ-UL;
/queue tree add name=UL_VID30_INT_UL packet-mark=VID30_INT_UL parent=UL_VID30 priority=8 queue=PCQ-UL max-limit=20M;
Повторяем дерево для второго сегмента (VID40)
Очередь сегмента:
/queue tree add name=DUPLEX-VID40 parent=ISP queue=default max-limit=40M;
Загрузка:
/queue tree add name=DL_VID40 parent=DUPLEX-VID40 queue=default;
/queue tree add name=DL_VID40_EXT_CLASS-A-FL_DL packet-mark=VID40_EXT_CLASS-A-FL_DL parent=DL_VID40 priority=5 queue=PCQ-DL;
/queue tree add name=DL_VID40_EXT_CLASS-B-FL_DL packet-mark=VID40_EXT_CLASS-B-FL_DL parent=DL_VID40 priority=6 queue=PCQ-DL;
/queue tree add name=DL_VID40_EXT_CLASS-A-UR_DL packet-mark=VID40_EXT_CLASS-A-UR_DL parent=DL_VID40 priority=4 queue=PCQ-DL;
/queue tree add name=DL_VID40_EXT_CLASS-B-UR_DL packet-mark=VID40_EXT_CLASS-B-UR_DL parent=DL_VID40 priority=5 queue=PCQ-DL;
/queue tree add name=DL_VID40_INT_DL packet-mark=VID40_INT_DL parent=DL_VID40 priority=7 queue=PCQ-DL max-limit=20M;
Отдача:
/queue tree add name=UL_VID40 parent=DUPLEX-VID40 queue=default;
/queue tree add name=UL_VID40_EXT_CLASS-A-FL_UL packet-mark=VID40_EXT_CLASS-A-FL_UL parent=UL_VID40 priority=6 queue=PCQ-UL;
/queue tree add name=UL_VID40_EXT_CLASS-B-FL_UL packet-mark=VID40_EXT_CLASS-B-FL_UL parent=UL_VID40 priority=7 queue=PCQ-UL;
/queue tree add name=UL_VID40_EXT_CLASS-A-UR_UL packet-mark=VID40_EXT_CLASS-A-UR_UL parent=UL_VID40 priority=5 queue=PCQ-UL;
/queue tree add name=UL_VID40_EXT_CLASS-B-UR_UL packet-mark=VID40_EXT_CLASS-B-UR_UL parent=UL_VID40 priority=6 queue=PCQ-UL;
/queue tree add name=UL_VID40_INT_UL packet-mark=VID40_INT_UL parent=UL_VID40 priority=8 queue=PCQ-UL max-limit=20M;
На этом все.
Естественно, что в адрес лист SHAPER_TARGET нужно вписать все диапазоны сегментов, а в списки VID30 и VID40 диапазоны сегментов которые на них находятся.
Теперь расскажу, как это работает.
Шейпер прозрачно пропускает через себя весь трафик до тех пор, пока не будет достигнут лимит, какой либо из родительских очередей. Простыми словами — пока хватает пропускной способности сегментов шейпер не работает, если же по сегменту идет большой трафик и превышает лимит — скорость режется в соответствии с приоритетами.
Как только лимит достигнут, приоритеты будут обработаны так:
Priority=4
Пропускается внешний трафик высокого приоритета на загрузку для юр.лиц.
Priority=5
Пропускается внешний трафик низкого приоритета на загрузку для юр.лиц. + Пропускается внешний трафик высокого приоритета на отдачу для юр.лиц. +
Пропускается внешний трафик высокого приоритета на загрузку для физ.лиц.
Priority=6
Пропускается внешний трафик низкого приоритета на загрузку для физ.лиц +
Пропускается внешний трафик высокого приоритета на отдачу для физ.лиц +
Пропускается внешний трафик низкого приоритета на отдачу для юр.лиц.
Priority=7
Пропускается межабонентский трафик на загрузку +
Пропускается внешний трафик низкого приоритета на отдачу для физ.лиц.
Priority=8
Пропускается межабонентский трафик на отдачу.
Данное поведение можно менять, изменяя приоритет у потомков в дереве, в данном случае приоритеты настроены «в нахлест» это позволяет «впихнуть невпихуемое» в сложных конфигурациях, когда восьми приоритетов не хватает. В данном же примере это лишь демонстрация возможностей.
Кроме всех приоритетов, на каждый сегмент наложено ограничение в сорок мегабит дуплекса. Это связано с радио и обсуждалось ранее. Так же принудительно ограничен обмен межабонентским трафиком по 20 мегабит на прием и 20 мегабит на отдачу в сегмент.
При обмене межабонентским трафиком между сегментами все будет регистрироваться правильно. На одном сегменте будет входящий трафик на другом исходящий. Но при обмене трафиком внутри сегмента будет зарегистрирован только исходящий из сегмента межабонентский трафик. Этого конечно можно было бы избежать, создав для каждого абонента индивидуальные правила маркировки, цена этому — пара тысяч правил в мангле.
Как я писал ранее, данные грабли возникают из-за того что один и тот же пакет попадает под критерии двух правил и победить данное поведение никак не получается.
Некоторые наверно подумали: «Внутри сегмента подсеть у всех одна, они общаются друг с другом напрямую (через базу или свитч). Как пакеты попали в маршрутизатор?».
Внутренний трафик нужно контролировать, либо запрещать. Броадкаст, вирусы, сканеры и прочая фигня очень пагубно влияют на сеть. Если на базе или свитче включить изоляцию абонентов, то они не смогут видеть друг друга в пределах этой базы или свитча. Но это, как бы, не совсем правильно и хорошо. Самый правильный вариант — это терминация индивидуальных VLAN, на коммутаторе или маршрутизаторе. Я использую аналог ip unnumbered для реализации межабонентского трафика и контроля над ним.
Но это уже совсем другая обширная тема.
Думаю, на этом стоит закончить, сей чудесный опус.
По традиции выкладываю готовые RSC последних примеров для импорта в систему, а так же адрес листы для добавления в приоритет серверов Wargaming, Warface и iccup. Дабы избавить вас от копипаста при проведении экспериментов.
Файл импорта RSC c контролем каналов, приоритезацией и тарифами (Первый роутер)
P.S Буду рад выслушать конструктивную критику и замечания по данным в примерах конструкциям. Так же буду рад общению и обмену опытом с опытными в данной сфере людьми. Мои контакты вы сможете найти в профиле.
Спасибо за внимание!
Автор: Inlarion