

14 мая, когда Трамп готовился спустить всех собак на Huawei, я мирно сидел в Шеньжене на Huawei STW 2019 — большой конференции на 1000 участников — в программе которой были доклады Филипа Вонга, вице-президента по исследованиям TSMC по перспективам не-фон-неймановских вычислительных архитектур, и Хенга Ляо, Huawei Fellow, Chief Scientist Huawei 2012 Lab, на тему разработки новой архитектуры тензорных процессоров и нейропроцессоров. TSMC, если знаете, делает нейроускорители для Apple и Huawei по технологии 7 nm (которой мало кто владеет), а Huawei по нейропроцессорам готова составить серьезную конкуренцию Google и NVIDIA.
Google в Китае забанен, поставить VPN на планшет я не удосужился, поэтому патриотично пользовался Яндексом для того, чтобы смотреть, какая ситуация у других производителей аналогичного железа, и что вообще происходит. В общем-то за ситуацией я следил, но только после этих докладов осознал, насколько масштабна готовящаяся в недрах компаний и тиши научных кабинетов революция.
Только в прошлом году в тему было вложено больше 3 миллиардов долларов. Google уже давно объявил нейросети стратегическим направлением, активно строит их аппаратную и программную поддержку. NVIDIA, почувствовав, что трон зашатался, вкладывает фантастические усилия в библиотеки ускорения нейросетей и новое железо. Intel в 2016 году потратил 0,8 миллиарда на покупку двух компаний, занимающихся аппаратным ускорением нейросетей. И это при том, что основные покупки еще не начались, а количество игроков перевалило за полсотни и быстро растет.

TPU, VPU, IPU, DPU, NPU, RPU, NNP — что все это означает и кто победит? Попробуем разобраться. Кому интересно — велкам под кат!
Disclaimer: Автору приходилось полностью переписывать алгоритмы обработки видео для эффективной реализации на ASIC, причем клиенты делали прототипирование на FPGA, поэтому представление о глубине разницы архитектур есть. Однако, непосредственно с железом в последнее время автор не работал. Но предчувствует, что вникать придется.
Предпосылки проблем
Количество требуемых вычислений бурно растет, народ с удовольствием взял бы больше слоев, больше вариантов архитектуры, активнее поигрался бы с гиперпараметрами, но… упирается в производительность. При этом, например, с ростом производительности старых добрых процессоров — большие проблемы. Все хорошее когда-нибудь заканчивается: закон Мура, как известно, иссякает и скорость роста производительности процессоров падает:

Расчеты реальной производительности целочисленных операций по SPECint по сравнению с VAX11-780, здесь и далее часто логарифмическая шкала
Если с середины 80-х по середину 2000-х — в благословенные годы расцвета компьютеров — рост шел со скоростью в среднем 52% в год, то последние годы он сократился до 3% в год. И это — проблема (перевод недавней статьи патриарха темы Джона Хеннесси о проблемах и перспективах современных архитектур был на Хабре).
Причин много, например, перестала расти частота процессоров:

Сложнее стало уменьшать размер транзисторов. Последняя напасть, кардинально снижающая производительность (в том числе — производительность уже выпущенных CPU) — это (барабанная дробь)… правильно, безопасность. Meltdown, Spectre и другие уязвимости наносят колоссальный ущерб скорости роста вычислительной мощности CPU (пример отключения hyperthreading(!)). Тема стала популярна, и новые уязвимости такого рода находят практически ежемесячно. И это — кошмар какой-то, поскольку больно бьет по производительности.
При этом развитие многих алгоритмов прочно завязано на ставший привычным рост мощности процессоров. Например, очень многие исследователи сегодня не парятся о скорости алгоритмов — что-нибудь да придумают. И ладно бы при обучении — сети становятся большими и «тяжелыми» для использования. Особенно это ярко видно на видео, для которого большинство подходов в принципе не применимы с высокой скоростью. А они имеют смысл часто только в реальном времени. Это тоже проблема.
Аналогично, сейчас развиваются новые стандарты сжатия, которые предполагают увеличение мощности декодеров. А если мощность процессоров не будет расти? Старшее поколение помнит, как в 2000-х возникали проблемы проиграть видео высокого разрешения в свежем тогда H.264 на старых компьютерах. Да, качество было лучше при меньшем размере, но на быстрых сценах картинка подвисала или звук рвался. Мне приходится общаться с разработчиками нового VVC/H.266 (релиз планируется на следующий год). Им не позавидуешь.
Итак, что век грядущий нам готовит в свете уменьшения скорости роста производительности процессоров в приложении к нейросетям?
CPU

Обычный CPU — это замечательная числодробилка, которую совершенствовали десятилетия. Увы, под другие задачи.
Когда мы работаем с нейросетями, особенно глубокими, у нас непосредственно сеть может занимать сотни мегабайт. К примеру, требования к памяти сетей обнаружения объектов такие:
| model | input size | param memory | feature memory |
| rfcn-res50-pascal | 600 x 850 | 122 MB | 1 GB |
| rfcn-res101-pascal | 600 x 850 | 194 MB | 2 GB |
| ssd-pascal-vggvd-300 | 300 x 300 | 100 MB | 116 MB |
| ssd-pascal-vggvd-512 | 512 x 512 | 104 MB | 337 MB |
| ssd-pascal-mobilenet-ft | 300 x 300 | 22 MB | 37 MB |
| faster-rcnn-vggvd-pascal | 600 x 850 | 523 MB | 600 MB |
По нашему опыту коэффициенты глубокой нейросети для обработки полупрозрачных границ могут занимать 150–200 Мб. У коллег в нейросети определения возраста и пола размер коэффициентов порядка 50 Мб. И при оптимизации для мобильной версии пониженной точности — порядка 25 Мб (float32⇒float16).
При этом график задержки при обращении к памяти в зависимости от размера данных распределяется примерно так (масштаб по горизонтали логарифмический):

Т.е. при увеличении объема данных больше 16 Мб задержка возрастает в 50 и более раз, что фатально сказывается на производительности. Фактически большую часть времени CPU при работе с глубокими нейросетями тупо ждет данных. Интересны данные Intel по ускорению разных сетей, где, фактически, ускорение идет, только когда сеть становится маленькой (например, в результате квантования весов), чтобы начать хотя бы частично входить в кэш вместе с обрабатываемыми данными. Заметим, что кэш современного CPU потребляет до половины энергии процессора. В случае тяжелых нейросетей он оказывается малоэффективен и работает неразумно дорогим обогревателем.
различных классификаторов объектов на изображении (где нейросеть нужно запустить большое число раз — 50–100 по числу объектов на изображении) и накладные расходы на запуск OpenVINO становятся неразумно велики.
Плюсы:
- «Есть у каждого», причем обычно простаивает, т.е. относительно низкая входная цена расчетов и внедрения.
- Есть отдельные не CV сети, которые хорошо ложатся на CPU, коллеги называют, например, Wide&Deep и GNMT.
Минус:
- CPU неэффективен при работе с глубокими нейросетями (когда число слоев сети и размер входных данных велики), все работает мучительно медленно.
GPU

Тема хорошо известна, поэтому бегло обозначим главное. У GPU в случае нейросетей существенное преимущество по производительности на массивно-параллельных задачах:

Обратите внимание, как отжигают 72-ядерный Xeon Phi 7290, при том, что «синий» — это тоже серверный Xeon, т.е. Intel так просто не сдается, о чем ниже еще будет. Но важнее то, что память у видеокарт изначально рассчитана под примерно в 5 раз более высокую производительность. В нейросетях вычисления с данными крайне простые. Несколько элементарных действий, и нам нужны новые данные. Как следствие, скорость доступа к данным является критичной для эффективной работы нейросети. Высокоскоростная память «на борту» GPU и более гибкая система управления кэш-памятью, чем на CPU, позволяет решить эту проблему:

Тим Детмерс уже несколько лет поддерживает интересный обзор «Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning» («Какой GPU лучше для глубокого обучения...»). Понятно, что для обучения рулят Теслы и Титаны, хотя разница архитектур может вызывать интересные всплески, например, в случае рекуррентных нейросетей (а лидер вообще TPU, заметим на будущее):

Однако, там есть крайне полезный график производительности за доллар, где на коне RTX (скорее всего за счет их Tensor cores), если вам её памяти хватает, конечно:

Безусловно, стоимость вычислений важна. Второе место первого рейтинга и последнее второго — Tesla V100 продается за 700 тысяч рублей, как 10 «обычных» компов (+ недешевый Infiniband коммутатор, если хочется обучать на нескольких узлах). Правда V100 и работает за десятерых. Люди готовы переплачивать за ощутимое ускорение обучения.
Итого, резюмируем!
Плюсы:
- Кардинальное — в 10–100 раз — ускорение работы по сравнению с CPU.
- Крайне эффективны для обучения (и несколько менее эффективны для применения).
Минус:
- Стоимость топовых видеокарт (памяти на которых достаточно для обучения сетей большого размера) превышает стоимость всего остального компьютера…
FPGA

FPGA — это уже интереснее. Это сеть из нескольких миллионов программируемых блоков, которые мы можем также программно соединять между собой. Сеть и блоки выглядят как-то так (тонкое место — Bottleneck, обратите внимание, опять перед памятью чипа, но все полегче, о чем будет ниже):

Естественно, применять FPGA имеет смысл уже на этапе применения нейросети (для обучения в большинстве случаев маловато памяти). Причем тема выполнения на FPGA сейчас начала активно развиваться. Например, вот фреймворк fpgaConvNet, помогающий заметно ускорить применение CNN на FPGA и снизить при этом энергопотребление.
Ключевой плюс FPGA в том, что мы можем хранить сеть непосредственно в ячейках, т.е. тонкое место в виде перегоняемых 25 раз в секунду (для видео) в одном и том же направлении сотен мегабайт одних и тех же данных волшебным образом пропадает. Что позволяет при более низкой тактовой частоте и отсутствии кэшей вместо понижения производительности получить заметное повышение. Да еще и кардинально снизить глобальное потепление энергопотребление на единицу вычислений.
К процессу активно подключился Intel, выпустив в прошлом году в открытых исходниках OpenVINO Toolkit, включающий в себя Deep Learning Deployment Toolkit (часть OpenCV). Причем производительность на FPGA на разных сетках выглядит довольно интересно, и преимущество у FPGA по сравнению с GPU (правда интегрированным GPU от Intel) весьма существенное:

Что особо греет душу автору — сравниваются FPS, т.е. кадры в секунду — наиболее практическая метрика для видео. С учетом того, что Intel в 2015 году купил второго по размеру игрока на рынке FPGA, компанию Altera, график дает хорошую пищу для размышлений.
И, очевидно, входной барьер в подобные архитектуры выше, поэтому должно пройти некоторое время, чтобы появились удобные инструменты, эффективно учитывающие принципиально иную архитектуру FPGA. Но недооценивать потенциал технологии не стоит. Уж больно много тонких мест она расшивает.
Напоследок подчеркнем, что программирование FPGA — это отдельное искусство. Как таковая программа там не выполняется, а все вычисления идут в терминах потоков данных, задержек потоков (что влияет на производительность) и использованных гейтов (которых всегда не хватает). Поэтому чтобы начать эффективно программировать — нужно основательно поменять собственную прошивку (в той нейросети, которая между ушами). С хорошей эффективностью это получается не у всех. Впрочем, новые фреймворки скоро скроют от исследователей внешнюю разницу.
Плюсы:
- Потенциально возможно более быстрое выполнение сети.
- Заметно ниже энергопотребление по сравнению с CPU и GPU (особенно это важно для мобильных решений).
Минусы:
- В основном помогают с ускорением выполнения, обучать на них, в отличие от GPU, заметно менее удобно.
- Более сложное программирование по сравнению с предыдущими вариантами.
- Заметно меньше специалистов.
ASIC

Далее идет ASIC — это сокращение от Application-Specific Integrated Circuit, т.е. интегральная схема под нашу задачу. Например, реализующая положенную в железо нейросеть. При этом большинство вычислительных узлов может работать параллельно. Фактически только зависимости по данным и неравномерность вычислений на разных уровнях сети могут помешать нам постоянно задействовать работающими все ALU.
Пожалуй, наибольшую рекламу ASIC среди широкой публики в последние годы сделал майнинг криптовалют. В самом начале майнинг на CPU был вполне рентабелен, позднее пришлось покупать GPU, потом — FPGA, а потом — специализированные ASIC, благо народ (читай — рынок) созрел для заказов, при которых их производство стало рентабельным.

В нашей области тоже уже появились (естественно!) сервисы, помогающие положить нейросеть на железо с необходимыми характеристиками по энергопотреблению, FPS и цене. Волшебно, согласитесь!
НО! Мы теряем настраиваемость сети. И, естественно, люди об этом тоже думают. Например, вот статья с говорящим названием "Can a reconfigurable architecture beat ASIC as a CNN accelerator?" («Может ли конфигурируемая архитектура побить ASIC, как акселератор CNN?»). Работ на эту тему хватает, ибо вопрос не праздный. Основной минус ASIC в том, что после того, как мы загнали сеть в железо, нам становится сложно ее поменять. Наиболее выгодны они для случаев, когда уже хорошо отлаженная сеть нам нужна миллионами чипов с низким энергопотреблением и высокой производительностью. И такая ситуация постепенно складывается на рынке автопилотов машин, например. Или в камерах видеонаблюдения. Или в камерах роботов-пылесосов. Или в камерах домашнего холодильника. Или в камере кофеварки. Или в камере утюга. Ну вы поняли идею, короче!

Важно, что при массовом производстве чип стоит дешево, работает быстро и потребляет минимум энергии.
Плюсы:
- Самая низкая стоимость чипа по сравнению со всеми предыдущими решениями.
- Самое низкое энергопотребление на единицу операций.
- Довольно высокая скорость работы (в том числе, при желании, рекордная).
Минусы:
- Очень ограничены возможности обновления сети и логики.
- Самая высокая стоимость разработки по сравнению со всеми предыдущими решениями.
- Использование ASIC рентабельно в основном при больших тиражах.
TPU
Напомним, при работе сетей есть две задачи — это обучение (training) и выполнение (inference). Если FPGA/ASIC ориентированы в первую очередь на ускорение выполнения (в том числе какой-то фиксированной сети), то TPU (Tensor Processing Unit или тензорные процессоры) — это либо аппаратное ускорение обучения, либо относительно универсальное ускорение работы произвольной сети. Название красивое, согласитесь, хотя по факту пока используются тензоры ранга 2 c Mixed Multiply Unit (MXU) соединенных с высокоскоростной памятью (High-Bandwidth Memory — HBM). Ниже схема архитектуры от TPU Google 2-й и 3-й версии:

TPU Google
Вообще рекламу названию TPU сделала Google, раскрыв внутренние разработки в 2017 году:

Предварительные работы по специализированным процессорам для нейросетей они начали с их слов еще в 2006, в 2013 создали проект с хорошим финансированием, а в 2015 начали работать с первыми чипами, которые сильно помогли с нейросетями для облачного сервиса Google Translate и не только. И это было, подчеркнем, ускорение выполнения сети. Важным преимуществом для дата-центров является на два порядка более высокая энергоэффективность TPU по сравнению с CPU (график для TPU v1):

Также, как правило, по сравнению с GPU в 10–30 раз в лучшую сторону отличается производительность выполнения сети:

Разница даже в 10 раз существенна. Понятно, что разница с GPU в 20–30 раз определяет развитие этого направления.
И, к счастью, Google не одинок.
TPU Huawei
Ныне многострадальный Huawei также начал разработку TPU несколько лет назад под именем Huawei Ascend, причем сразу в двух версиях — для дата-центров (как Google) и для мобильных устройств (что Google тоже начал делать недавно). Если верить материалам Huawei, то они обогнали свежий Google TPU v3 по FP16 в 2,5 раза и NVIDIA V100 в 2 раза:

Как обычно хороший вопрос: как этот чип поведет себя на реальных задачах. Ибо на графике, как видим, пиковая производительность. Кроме того, Google TPU v3 хорош во многом тем, что умеет эффективно работать в кластерах по 1024 процессора. Huawei тоже заявила серверные кластера для Ascend 910, но подробностей нет. В целом инженеры Huawei показывают себя крайне грамотными последние 10 лет, и есть все шансы, что в 2,8 раз большая пиковая производительность по сравнению с Google TPU v3 вкупе с новейшим техпроцессом 7 nm будут использованы по делу.
Критичным для производительности являются память и шина данных, и по слайду видно, что внимание этим компонентам уделено значительное (в том числе скорость общения с памятью заметно быстрее, чем у GPU):

Также в чипе идет несколько другой подход — масштабируются не двумерные MXU 128x128, а вычисления в трехмерном кубе меньшего размера 16х16хN, где N={16,8,4,2,1}. Поэтому ключевой вопрос — насколько хорошо это ляжет на реальное ускорение конкретных сетей (например, вычисления в кубе удобны для изображений). Также, при внимательном изучении слайда видно, что в отличие от Google в чип сразу закладывается работа со сжатым FullHD видео. Для автора это звучит очень обнадеживающе!
Как упоминалось выше, в той же линейке разрабатываются процессоры для мобильных устройств, для которых критична энергоэффективность, и на которых сеть будет в основном выполняться (т.е. отдельно — процессоры для облачного обучения и отдельно — для выполнения):

И по этому параметру все смотрится неплохо по сравнению с NVIDIA по крайней мере (заметим, что с Google они сравнение не привели, правда, Google в руки облачные TPU не дает). А их мобильные чипы будут конкурировать с процессорами от Apple, Google и других компаний, но тут пока рано подводить итоги.
Хорошо видно, что новые чипы Nano, Tiny и Lite должны быть еще лучше. Становится понятно, чего испугался Трамп почему многие производители внимательно изучают успехи Huawei (обогнавшей по выручке все компании-производители железа в США, включая Intel в 2018 году).
Аналоговые глубокие сети
Как известно — техника часто развивается по спирали, когда на новом витке актуальными становятся старые и забытые подходы.
Нечто подобное вполне может произойти с нейросетями. Вы, возможно, слышали, что когда-то операции умножения и сложения выполнялись электронными лампами и транзисторами (например, преобразование цветовых пространств — типичное перемножение матриц — было в каждом цветном телевизоре до середины 90-х)? Возник хороший вопрос: если уж наша нейронная сеть относительно устойчива к неточным вычислениям внутри, что если мы переведем эти вычисления в аналоговый вид? Мы с ходу получаем заметное ускорение вычислений и потенциально кардинальное снижение расхода энергии на выполнение одной операции:

При таком подходе DNN (Deep Neural Network) вычисляется быстро и энергоэффективно. Но есть проблема — это ЦАП/АЦП (DAC/ADC) — преобразователи из цифры в аналог и обратно, которые уменьшают и энергоэффективность, и точность процесса.
Впрочем, еще в 2017 году в IBM Research предложили аналоговые CMOS для RPU (Resistive Processing Units), которые позволяют хранить обрабатываемые данные также в аналоговом виде и существенно повысить общую эффективность подхода:

Также, помимо аналоговой памяти сильно может помочь снижение точности нейросети — это ключ к миниатюризации PRU, а значит, к увеличению числа вычислительных ячеек на кристалле. И здесь IBM также в лидерах, а частности недавно в этом году они вполне успешно до 2-битной точности огрубили сеть и собираются довести точность до однобитной (и двухбитной при тренировках), что потенциально позволит в 100 раз (!) поднять производительность по сравнению с современными GPU:

Говорить предметно про аналоговые нейрочипы пока рано, поскольку пока всё это тестируется на уровне ранних прототипов:

Однако, потенциально направление аналоговых вычислений выглядит предельно интересно.
Единственное, что смущает — что это IBM, подавшая уже десятки патентов по теме. По опыту, в силу особенностей корпоративной культуры, они относительно слабо кооперируются с другими компаниями и, владея какой-то технологией, скорее склонны затормозить ее развитие у других, чем эффективно поделиться. Например, IBM в свое время отказались лицензировать арифметическое сжатие для JPEG комитету ISO при том, что в драфте стандарта был вариант с арифметическим сжатием. В итоге JPEG ушел в жизнь со сжатием по Хаффману и жал на 10–15% хуже, чем мог бы. Та же ситуация была со стандартами сжатия видео. А индустрия массово перешла на арифметическое сжатие в кодеках только когда 5 патентов IBM истекли 12 лет спустя… Будем надеяться, что в IBM будут более склонны к кооперации в этот раз, и, соответственно, пожелаем максимальных успехов в области всем, кто не связан с IBM, благо таких людей и компаний немало.
Если получится — это будет революция в применении нейросетей и переворот во многих областях computer science.
Разные другие буквы
Вообще, тема ускорения нейросетей стала модной, ей занимаются все крупные компании и десятки стартапов, и как минимум 5 из них привлекли более 100 миллионов долларов инвестиций к началу 2018 года. Всего же в 2017 в стартапы, связанные с разработкой чипов, было инвестировано 1,5 МИЛЛИАРДА долларов. При том, что инвесторы не замечали чипмейкеров добрых 15 лет (ибо ловить там на фоне гигантов было нечего). В общем — сейчас появился реальный шанс на небольшую железную революцию. Причем предсказать, какая архитектура победит крайне сложно, необходимость в революции назрела, а возможности в увеличении производительности велики. Созрела классическая революционная ситуация: Мур уже не может, а Дин еще не готов.
Ну а поскольку важнейший рыночный закон — отличайся, появилось много новых букв, например:
- Neural Processing Unit (NPU) — Нейропроцессор, иногда красиво — нейроморфный чип — вообще говоря, общее название для акселератора нейросетей, каковым называют чипы Samsung, Huawei и далее по списку…

Здесь и далее в этом разделе будут приведены в основном слайды корпоративных презентаций в качестве примеров самоназваний технологий
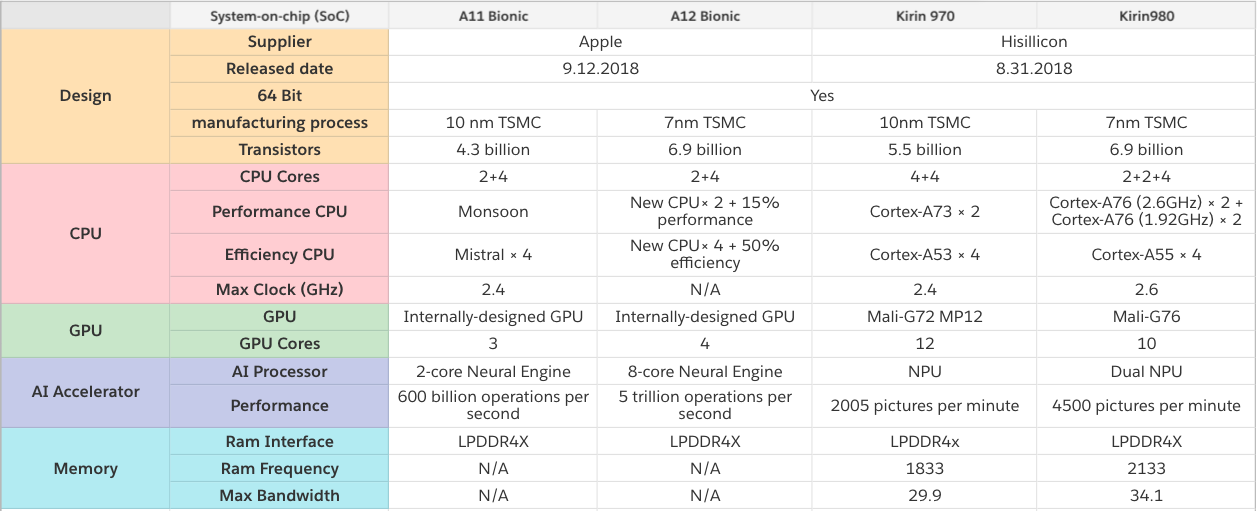
Понятно, что прямое сравнение проблематично, но вот любопытные данные, сравнивающие чипы с нейропроцессорами от Apple и Huawei, производимые упоминавшейся в начале TSMC. Видно, что соревнование идет жесткое, новое поколение показывает прирост производительности в 2-8 раз и усложнение технологических процессов:

- Neural Network Processor (NNP) — Нейросетевой процессор.

Так называет свое семейство чипов, например, Intel (изначально это была компания Nervana Systems, которую Intel купила в 2016 за $400+ миллионов). Впрочем, и в статьях, и в книгах название NNP тоже вполне встречается.
- Intelligence Processing Unit (IPU) — интеллектуальный процессор — название чипов, продвигаемое компанией Graphcore (кстати, получившей уже $310 миллионов инвестиций).

Она выпускает специальные карты для компьютеров, но заточенные на обучение нейросетей, с производительностью на обучении RNN в 180–240 раз выше, чем у NVIDIA P100.
- Dataflow Processing Unit (DPU) — процессор обработки потока данных — название продвигается компанией WAVE Computing, получившей уже $203 миллиона инвестиций. Выпускает примерно такие же акселераторы, как и Graphcore:

Поскольку они получили на 100 миллионов меньше, они декларируют обучение всего в 25+ раз быстрее, чем на GPU (правда обещают, что скоро будет 1000 раз). Посмотрим…
- Vision Processing Unit (VPU) — Процессор компьютерного зрения:

Термин используется в продуктах нескольких компаний, например, Myriad X VPU от Movidius (тоже была куплена Intel в 2016).
- Один из конкурентов IBM (которые, напомним, используют термин RPU) — компания Mythic — двигают Analog DNN, в которых также идет хранение сети в чипе и относительно быстрое выполнение. Пока у них только обещания, правда серьезные:

{kind=link}
И это перечислены только наиболее крупные направления, в развитие которых вложены сотни миллионов (при разработке железа это важно).
В общем, как видим, бурно расцветают все цветы. Постепенно компании переварят миллиарды долларов инвестиций (обычно на производство чипов требуется 1,5–3 года), пыль осядет, лидер станет понятен, победители, как обычно, напишут историю, и название наиболее успешной на рынке технологии станет общепринятым. Так уже было не раз («IBM PC», «Smartphone», «ксерокс» и т.д.).
Пара слов про корректное сравнение
Как уже было замечено выше, корректно сравнивать производительность нейросетей непросто. Ровно поэтому Google публикует график, на котором TPU v1 делает NVIDIA V100. NVIDIA, видя такое безобразие, публикует график, где Google TPU v1 проигрывает V100. (Дык!) Google публикует следующий график, где V100 с треском проигрывает Google TPU v2 & v3. И, наконец, Huawei — график, где все с треском проигрывают Huawei Ascend, но V100 лучше TPU v3. Цирк, короче. Что характерно — своя правда есть в каждом графике!
Первопричины ситуации понятны:
- Можно измерять скорость обучения или скорость выполнения (в зависимости от того, что удобнее).
- Можно измерять разные нейросети, поскольку скорость выполнения/обучения разных нейросетей на конкретных архитектурах может заметно отличаться из-за архитектуры сети и объема требуемых данных.
- А можно измерять пиковую производительность акселератора (пожалуй, наиболее абстрактную величину из всех, приведенных выше).
В качестве попытки навести порядок в этом зоопарке появился тест MLPerf, у которого сейчас доступна версия 0.5, т.е. он находится в процессе формирования методологии сравнения, довести которую до первого релиза планируют в 3 квартале этого года:

Поскольку в авторах там один из основных контрибьюторов TensorFlow, есть все шансы узнать, на чем быстрее всего обучать и, возможно, использовать (ибо мобильную версию TF со временем скорее всего в этот тест также включат).
Недавно международная организация IEEE, издающая третью часть мировой технической литературы по радиоэлектронике, компьютерам и электротехнике, не по-детски забанила Huawei, вскоре, впрочем, отменив бан. В текущем рейтинге MLPerf Huawei пока отсутствует, при том Huawei TPU является серьезным конкурентом Google TPU и карт NVIDIA (т.е. помимо политических, есть и экономические причины игнорировать Huawei, скажем прямо). С нескрываемым интересом будем следить за развитием событий!
Все в небо! Ближе к облакам!
И, раз уж речь пошла об обучении, стоит несколько слов сказать про его специфику:
- С повальным уходом исследований в глубокие нейросети (с десятками и сотнями слоев, которые действительно всех рвут) потребовалось перемалывать сотни мегабайт коэффициентов, что немедленно сделало неэффективными все кэши процессоров предыдущих поколений. При этом на классическом ImageNet рассуждают о строгой корреляции между размером сети и ее точностью (чем выше, тем лучше, чем правее, тем больше сеть, горизонтальная ось логарифмическая):

- Ход вычислений внутри нейросети идет по фиксированной схеме, т.е. где будут происходить все «ветвления» и «переходы» (в терминах прошлого века) в подавляющем большинстве случаев точно известно заранее, что оставляет без работы спекулятивное исполнение инструкций, ранее заметно повышающее производительность:

Это делает неэффективными навороченные суперскалярные механизмы предсказания ветвления и предвычислений предыдущих десятилетий совершенствования процессоров (эта часть чипа тоже, к сожалению, на DNN скорее способствует глобальному потеплению, как и кэш). - При этом обучение нейросети относительно слабо масштабируется горизонтально. Т.е. мы не можем взять 1000 мощных компьютеров и получить ускорение обучения в 1000 раз. И даже в 100 не можем (по крайней мере пока не решена теоретическая проблема ухудшения качества обучения на большом размере батча). Нам вообще довольно сложно что-то раздавать по нескольким компьютерам, поскольку как только падает скорость доступа к единой памяти, в которой лежит сеть — катастрофически падает скорость ее обучения. Поэтому если у исследователя будет доступ к 1000 мощных компьютеров
на халяву, он, безусловно, скоро их все займет, но скорее всего (если там не infiniband + RDMA) обучаться там будет много нейросетей с разными гиперпараметрами. Т.е. общее время обучения будет лишь в несколько раз меньше, чем при 1 компьютере. Там возможны и игра с размерами батча, и дообучение, и прочие новые модные технологии, но основной вывод — да, при увеличении количества компьютеров эффективность работы и вероятность достичь результата будут расти, но не линейно. Причем сегодня время исследователя Data Science стоит дорого и часто если можно потратить много машин (пусть неразумно), но получить ускорение — это делается (см. пример с 1, 2 и 4 дорогими V100 в облаках чуть ниже).
{kind=link}
Ровно эти моменты объясняют, почему так много народу рвануло в сторону разработки специализированного железа для глубоких нейросетей. И почему они получили свои миллиарды. Там действительно виден свет в конце туннеля и не только у Graphcore (которые, напомним, в 240 раз обучение RNN ускорили).
Например, господа из IBM Research полны оптимизма, разработать спец-чипы, которые уже через 5 лет на порядок поднимут эффективность вычислений (а через 10 лет на 2 порядка, достигнув увеличения в 1000 раз по сравнению с уровнем 2016 года, на данном графике, правда, в эффективности на ватт, но мощность ядер при этом тоже вырастет):

Все это означает появление железок, обучение на которых будет относительно быстрым, но стоить которые будут дорого, что естественным образом приводит к идее разделять время использования этой дорогой железки между исследователями. А эта идея сегодня не менее естественно приводит нас к облачным вычислениям. И переход обучения в облака уже давно активно идет.
Заметим, что уже сейчас обучение одних и тех же моделей может отличаться по времени на порядок у разных облачных сервисов. Ниже лидирует Amazon, а на последнем месте бесплатный Colab от Google. Обратите внимание, как изменяется результат от количества V100 у лидеров — увеличение числа карт в 4 раза(!) повышает производительность менее, чем на треть (!!!) — с голубого до фиолетового, а у Google и того меньше:

Похоже, в ближайшие годы различие вырастет до двух порядков. Господа! Готовим деньги! Будем дружно возвращать многомиллиардные инвестиции наиболее успешным инвесторам…
Если кратко
Попробуем резюмировать ключевые моменты в табличку:
| Тип | Что ускоряет | Комментарий |
| CPU | В основном выполнение | Обычно худшие по скорости и энергоэффективности, но вполне пригодны для выполнения небольших по размеру нейросетей |
| GPU | Выполнение+ обучение |
Наиболее универсальное решение, но довольно дорогое, как по стоимости вычислений, так и по энергоэффективности |
| FPGA | Выполнение | Относительно универсальное решение для исполнения сетей, в некоторых случаях позволяет кардинально ускорить выполнение |
| ASIC | Выполнение | Наиболее дешевый, быстрый и энергоэффективный вариант исполнения сети, но нужны большие тиражи |
| TPU | Выполнение+ обучение |
Первые версии использовались для ускорения выполнения, сейчас используются для весьма эффективного ускорения выполнения и обучения |
| IPU, DPU… NNP | В основном обучение | Много маркетинговых букв, которые благополучно забудут в ближайшие годы. Основной плюс этого зоопарка — проверка разных направлений ускорения DNN |
| Analog DNN / RPU | Выполнение+ обучение |
Потенциально аналоговые ускорители могут произвести революцию в скорости и энергоэффективности выполнения и обучения нейросетей |
Пара слов про программное ускорение
Справедливости ради упомянем, что сегодня большая тема — программное ускорение выполнения и обучения глубоких нейросетей. Выполнение можно заметно ускорить в первую очередь за счет так называемого квантования сети. Возможно это, во-первых, поскольку используемый диапазон значений весов не так велик и зачастую можно огрубить значения весов с 4-байтового значения с плавающей точкой до 1 байтового целого (и, вспоминая успехи IBM, даже сильнее). Во-вторых, обученная сеть в целом довольно устойчива к шуму в вычислениях и точность работы при переходе к int8 падает незначительно. При этом, несмотря на то, что количество операций может даже возрасти (за счет масштабирования при счете), то, что сеть уменьшается в размере в 4 раза и может считаться быстрыми векторными операциями ощутимо поднимает общую скорость выполнения. Особенно это важно для мобильных приложений, но и в облаках вполне работает (пример ускорения выполнения в облаках Amazon):

Есть и другие способы алгоритмического ускорения выполнения сети и еще больше способов ускорения обучения. Впрочем, это отдельные большие темы, про которые не в этот раз.
Вместо заключения
В своих лекциях инвестор и автор Тони Себа приводит великолепный пример: в 2000 году суперкомпьютер №1 производительностью 1 терафлопс занимал 150 квадратных метров, стоил 46 миллионов долларов и потреблял 850 кВт:

15 лет спустя GPU NVIDIA производительностью 2.3 терафлопса (в 2 раза больше) помещался в руке, стоил 59$ (улучшение примерно в миллион раз) и потреблял 15 Вт (улучшение в 56 тысяч раз):

В марте этого года Google представила TPU Pods — фактически суперкомпьютеры с жидкостным охлаждением на основе TPU v3, ключевым свойством которых является то, что они могут работать совместно в системах по 1024 TPU. Выглядят они довольно впечатляюще:

Точные данные не приводятся, но говорится, что система сопоставима с Top-5 суперкомпьютеров мира. TPU Pod позволяет кардинально повысить скорость обучения нейросетей. Для увеличения скорости взаимодействия TPU соединены высокоскоростными магистралями в тороидальную структуру:

Похоже, через 15 лет этот нейропроцессор вдвое большей производительности тоже вполне сможет поместиться в руке, как Skynet processor (согласитесь, чем-то похож):

Кадр из режиссерской версии фильма «Терминатор-2»
Учитывая текущую скорость совершенствования аппаратных акселераторов глубоких нейросетей и пример выше, это совершенно реально. Есть все шансы через несколько лет взять в руку чип, производительностью, как сегодняшний TPU Pod.
Кстати, забавно, что в фильме создатели чипа (видимо, представляя себе, куда может завести сеть самообучение) по умолчанию отключили дообучение. Характерно, что сам T-800 не мог включить training mode и работал в режиме inference mode (см. более длинную режиссерскую версию). Причем его neural-net processor был продвинутым и при включении дообучения мог использовать ранее накопленные данные для обновления модели. Неплохо для 1991 года.
Этот текст был начат в жарком 13-миллионном Шеньжене. Я сидел в одном из 27 000 электротакси города и с большим интересом рассматривал 4 жидкокристаллических экрана машины. Один маленький — среди приборов перед водителем, два — по центру в торпеде и последний — полупрозрачный — в зеркале заднего вида, совмещенный с видеорегистратором, камерой видеонаблюдения салона и андроидом на борту (судя по верхней строке с уровнем заряда и связи с сетью). Там отображались данные водителя (на кого жаловаться, если что), свежий прогноз погоды и, похоже, была связь с таксопарком. Водитель не знал английского, и поспрашивать его про впечатления от электромашины не получилось. Поэтому он лениво давил педаль, чуть продвигая машину в пробке. А я с интересом наблюдал за окном футуристичный вид — китайцы в пиджаках ехали с работы на электросамокатах и моноколесах… и размышлял, как все это будет выглядеть через 15 лет…
Собственно, уже сегодня зеркало заднего вида, пользуясь данными камеры видеорегистратора и аппаратной акселерацией нейросетей, вполне в состоянии управлять машиной в пробке и прокладывать маршрут. Днем, по крайней мере ). Через 15 лет система явно будет не только в состоянии водить машину, но и с удовольствием предоставит мне характеристики свежих китайских электромобилей. На русском, естественно (как вариант: английском, китайском… албанском, наконец). Водитель тут лишнее, слабо обучаемое, звено.
Господа! Нас ждут ПРЕДЕЛЬНО ИНТЕРЕСНЫЕ 15 лет!
Stay tuned!
I’ll be back! )))

- Лабораторию Компьютерной Графики ВМК МГУ им. М.В.Ломоносова за вклад в развитие компьютерной графики в России и не только,
- наших коллег, Михаила Ерофеева и Никиту Багрова, чьи примеры использованы выше,
- персонально Константина Кожемякова, который сделал очень много для того, чтобы эта статья стала лучше и нагляднее,
- и, наконец, огромное спасибо Александру Бокову, Михаилу Ерофееву, Виталию Людвиченко, Роману Казанцеву, Никите Багрову, Ивану Молодецких, Егору Склярову, Алексею Соловьеву, Евгению Ляпустину, Сергею Лаврушкину и Николаю Оплачко за большое количество дельных замечаний и правок, сделавших этот текст намного лучше!
Автор: Dmitriy Vatolin