


В этом посте мы реализуем с нуля GPT всего в 60 строках numpy. Затем мы загрузим в нашу реализацию опубликованные OpenAI веса обученной модели GPT-2 и сгенерируем текст.
Примечание:
- Для понимания этого поста нужно разбираться в Python, NumPy и обладать начальным опытом в обучении нейросетей.
- В этой реализации отсутствует большая часть функциональности; это сделано намеренно, чтобы максимально упростить её, при этом сохранив целостность. Моя задача — создание простого, но завершённого технического введения в GPT как обучающего инструмента.
- Понимание архитектуры GPT — всего лишь небольшая (хотя и жизненно важная) часть более масштабной темы больших языковых моделей (LLM). [Масштабное обучение, сбор терабайтов данных, обеспечение быстрой работы модели, оценка производительности и подстройка моделей под выполнение необходимых человеку задач — дело всей жизни для сотен инженеров и исследователей, работа которых потребовалась, чтобы превратить LLM в то, чем они являются сегодня; одной лишь архитектуры недостаточно. Архитектура GPT просто оказалась первой архитектурой нейросетей, обладающей удобными свойствами масштабирования, высокой параллелизации на GPU и качественного моделирования последовательностей. Настоящим секретным ингредиентом становится масштабирование данных и модели (как обычно), а GPT именно это и позволяет нам делать. Возможно, трансформер просто выиграл в аппаратную лотерею и рано или поздно какая-то другая архитектура сбросит его с трона.]
- Весь код из этого поста выложен в github.com/jaymody/picoGPT.
Что такое GPT?
GPT расшифровывается как Generative Pre-trained Transformer. Этот тип архитектуры нейросети основан на трансформере. Статья How GPT3 Works Джея Аламмара — прекрасное высокоуровневое введение в GPT, которое вкратце можно изложить так:
- Generative: GPT генерирует текст.
- Pre-trained: GPT обучается на множестве текстов из книг, Интернета и так далее
- Transformer: GPT — это нейронная сеть, содержащая в себе только декодирующий трансформер.
Большие языковые модели (Large Language Model, LLM) наподобие GPT-3 компании OpenAI, LaMDA компании Google и Command XLarge компании Cohere по своему строению являются всего лишь GPT. Особенными их делает то, что они 1) очень большие (миллиарды параметров) и 2) обучены на множестве данных (сотни гигабайтов текста).
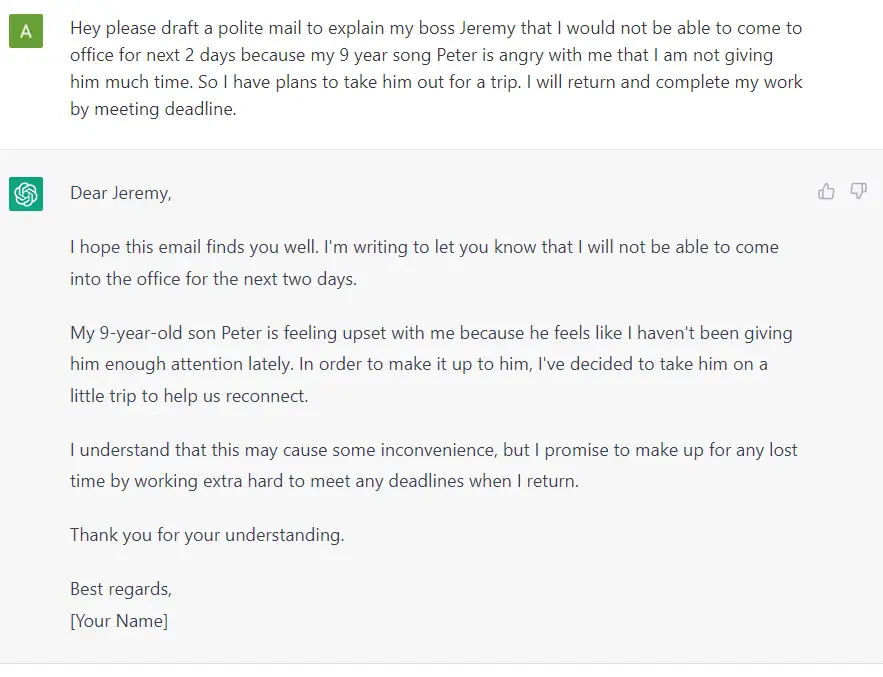
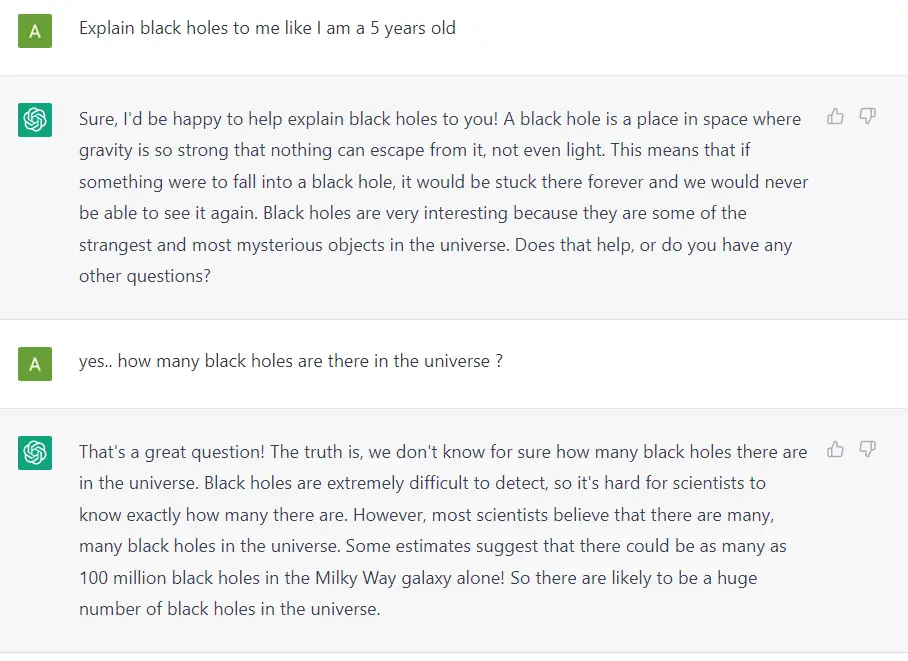
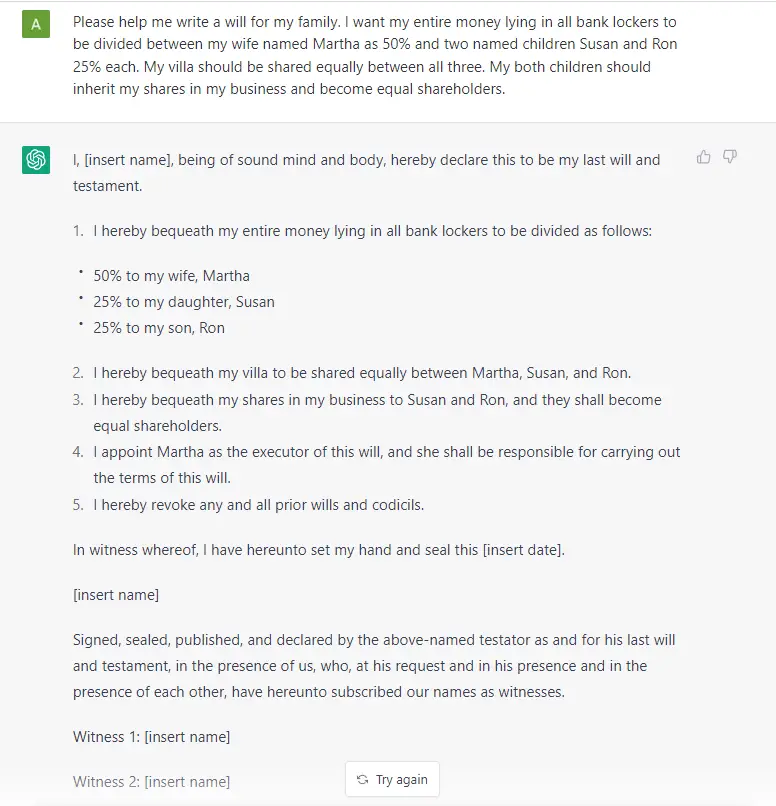
По сути, GPT генерирует текст на основании промпта (запроса). Даже при этом очень простом API (на входе текст, на выходе текст), хорошо обученная GPT способна выполнять потрясающие задачи, например, писать за вас электронные письма, составить резюме книги, давать идеи подписей к постам в соцсетях, объяснить чёрные дыры пятилетнему ребёнку, писать код на SQL и даже составить завещание.
Это было краткое описание GPT и их возможностей. А теперь давайте углубимся в подробности.
Ввод и вывод
Сигнатура функции GPT выглядит примерно так:
def gpt(inputs: list[int]) -> list[list[float]]:
# вводы имеют форму [n_seq]
# выводы имеют форму [n_seq, n_vocab]
output = # бип-бип, магия нейронной сети
return outputВвод
Вводом является последовательность целых чисел, представляющих собой токены некоторого текста:
# целые числа обозначают токены в нашем тексте, например:
# текст = "not all heroes wear capes":
# токены = "not" "all" "heroes" "wear" "capes"
inputs = [1, 0, 2, 4, 6]Мы определяем целочисленное значение токена на основании вокабулярия токенизатора:
# индекс токена в вокабулярии обозначает целочисленный идентификатор этого токена
# например, целочисленный идентификатор для "heroes" будет равен 2, так как vocab[2] = "heroes"
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
# имитация токенизатора, выполняющая токенизацию по пробелу
tokenizer = WhitespaceTokenizer(vocab)
# метод encode() выполняет преобразование str -> list[int]
ids = tokenizer.encode("not all heroes wear") # ids = [1, 0, 2, 4]
# мы видим реальные токены при помощи сопоставления вокабулярия
tokens = [tokenizer.vocab[i] for i in ids] # tokens = ["not", "all", "heroes", "wear"]
# метод decode() выполняет обратное преобразование list[int] -> str
text = tokenizer.decode(ids) # text = "not all heroes wear"Вкратце:
- У нас есть строка.
- Мы используем токенизатор, чтобы разбить её на части меньшего размера, называемые токенами.
- Далее мы применяем вокабулярий, чтобы сопоставить токены с целочисленными значениями.
На практике используются более сложные методы токенизации, чем простое разбиение по пробелам, например, Byte-Pair Encoding или WordPiece, но принцип остаётся тем же:
- Существует
vocab, сопоставляющий токены строк с целочисленными индексами - Есть метод
encode, выполняющий преобразованиеstr -> list[int] - Есть метод
decode, выполняющий преобразованиеlist[int] -> str
Вывод
Выводом является 2D-массив, в котором output[i][j] — это прогнозируемая вероятность модели того, что токен в vocab[j] является следующим токеном inputs[i+1]. Например:
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[0] = [0.75 0.1 0.0 0.15 0.0 0.0 0.0 ]
# на основе одного "not" модель с наибольшей вероятностью прогнозирует слово "all"
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[1] = [0.0 0.0 0.8 0.1 0.0 0.0 0.1 ]
# на основе последовательности ["not", "all"] модель с наибольшей вероятностью прогнозирует слово "heroes"
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[-1] = [0.0 0.0 0.0 0.1 0.0 0.05 0.85 ]
# на основе полной последовательности ["not", "all", "heroes", "wear"] модель с наибольшей вероятностью прогнозирует слово "capes"
Чтобы получить прогноз следующего токена для всей последовательности, мы просто берём токен с наибольшей вероятностью в output[-1]:
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
next_token_id = np.argmax(output[-1]) # next_token_id = 6
next_token = vocab[next_token_id] # next_token = "capes"Взятие токена с наибольшей вероятностью в качестве окончательного прогноза часто называют greedy decoding (жадным декодированием) или greedy sampling (жадным сэмплированием).
Задача прогнозирования следующего логичного слова в тексте называется языковым моделированием. Поэтому можно назвать GPT языковой моделью.
Генерировать одно слово — это, конечно, здорово, но как насчёт генерации целых предложений, абзацев и так далее?
Генерация текста
Авторегрессивная
Мы можем генерировать законченные предложения, итеративно запрашивая у модели прогноз следующего токена. На каждой итерации мы добавляем спрогнозированный токен к вводу:
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # цикл авторегрессивного декодирования
output = gpt(inputs) # прямой проход модели
next_id = np.argmax(output[-1]) # жадное сэмплирование
inputs = np.append(out, [next_id]) # добавление прогноза к вводу
return list(inputs[len(inputs) - n_tokens_to_generate :]) # возвращаем только сгенерированные id
input_ids = [1, 0] # "not" "all"
output_ids = generate(input_ids, 3) # output_ids = [2, 4, 6]
output_tokens = [vocab[i] for i in output_ids] # "heroes" "wear" "capes"Этот процесс прогнозирования будущего значения (регрессия) и добавление его обратно во ввод («авто») и стал причиной того, что модель GPT иногда называют авторегрессивной.
Сэмплирование
Мы можем добавить генерированию стохастичности (случайности), выполняя сэмплирование не жадным образом, а из распределения вероятностей:
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # hats
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # pantsЭто не только позволяет нам генерировать разные предложения по одному вводу, но и повышает качество выводов по сравнению с жадным декодированием.
Также часто используются техники наподобие top-k, top-p и temperature для изменения распределения вероятностей перед сэмплированием из него. Это ещё больше увеличивает качество генераций и добавляет гиперпараметры, с которыми можно экспериментировать для получения разного поведения генераций (например, повышение «температуры» увеличивает рискованность модели, делая её более «творческой»).
Если вы хотите почитать анализ других техник сэмплирования для управления генерациями языковых моделей, рекомендую Controllable Neural Text Generation Лиллиан Венг.
Обучение
Мы обучаем GPT как любую другую нейросеть — при помощи градиентного спуска с учётом некоей функции потерь. В случае GPT мы берём потерю перекрёстной энтропии для задачи языкового моделирования:
def lm_loss(inputs: list[int], params) -> float:
# метки y - это просто input, сдвинутый на 1 влево
#
# inputs = [not, all, heros, wear, capes]
# x = [not, all, heroes, wear]
# y = [all, heroes, wear, capes]
#
# разумеется, у нас нет метки для inputs[-1], поэтому мы исключаем её из x
#
# поэтому для N вводов у нас будет N - 1 примеров пар для языкового моделирования
x, y = inputs[:-1], inputs[1:]
# прямой проход
# все распределения вероятностей спрогнозированных следующих токенов на каждой позиции
output = gpt(x, params)
# потеря перекрёстной энтропии
# мы берём среднее по всем N-1 примерам
loss = np.mean(-np.log(output[y]))
return loss
def train(texts: list[list[str]], params) -> float:
for text in texts:
inputs = tokenizer.encode(text)
loss = lm_loss(inputs, params)
gradients = compute_gradients_via_backpropagation(loss, params)
params = gradient_descent_update_step(gradients, params)
return params
Для понятности мы добавили аргумент params ко вводу gpt. При каждой итерации цикла обучения мы выполняем этап градиентного спуска для обновления параметров модели, делая нашу модель всё лучше и лучше в моделировании языка с каждым новым фрагментом текста, который она видит. Это крайне упрощённая структура обучения, однако она демонстрирует процесс в целом.
Обратите внимание, что мы не используем явным образом размеченные данные. Создавать пары input/label можно и просто из сырого текста. Это называется self-supervised learning (самообучением).
Это означает, что мы можем очень просто масштабировать объём данных обучения, всего лишь показывая модели как можно большее количество сырых текстов. Например, GPT-3 была обучена на 300 миллиардах токенов текста из Интернета и книг:

Таблица 2.2 из статьи о GPT-3
Чтобы учиться на всех этих данных, нам нужна модель существенно бОльших размеров, поэтому GPT-3 имеет 175 миллиардов параметров, а вычислительные затраты на её обучение приблизительно составляют $1-10 миллионов. [Однако после статей про InstructGPT и Chinchilla мы осознали, что на самом деле необязательно обучать столь огромные модели. Оптимально обученная и подстроенная на основе инструкций GPT с 1,3 миллиардами параметров может превзойти GPT-3 с 175 миллиардами параметров.]
Этот этап самообучения называется pre-training (предварительным обучением), поскольку мы можем повторно использовать веса «предварительно обученных» моделей для дальнейшего обучения модели для следующих задач, например, для определения токсичности твита.
Обучение модели на углублённых задачах называется fine-tuning (подстройкой), поскольку веса модели уже были предварительно обучены пониманию языка и всего лишь подстраиваются под конкретную задачу.
Стратегия «предварительное обучение на общей задаче + подстройка на конкретной задаче» называется трансферным обучением.
Промптинг
В принципе, исходная GPT просто использовала преимущества предварительного обучения модели трансформера для трансферного обучения, аналогично BERT.
И только после появления научных статей о GPT-2 and GPT-3 мы осознали, что предварительно обученная модель GPT сама по себе способна выполнять любую задачу просто после создания промпта и выполнения авторегрессивного языкового моделирования, без необходимости подстройки. Это называется in-context learning (обучением в контексте), поскольку для выполнения задачи модель использует только контекст промпта. Обучение в контексте может быть без примеров (zero shot), с одним (one shot) или несколькими (few shot) примерами:

Иллюстрация 2.1 из научной статьи про GPT-3
Разумеется, можно использовать GPT в качестве чат-бота, а не заставлять её выполнять «задачи». История беседы передаётся в модель в качестве промпта, возможно, с каким-то предварительным описанием, например «Ты чат-бот, веди себя хорошо». Если изменить промпт, можно даже придать чат-боту черты личности.
Разобравшись со всем этим, можно, наконец, перейти к реализации!
Подготовка
Клонируйте репозиторий для этого туториала:
git clone https://github.com/jaymody/picoGPT
cd picoGPTТеперь давайте установим зависимости:
pip install -r requirements.txt
Учтите, что если вы работаете на Macbook с M1, то прежде чем выполнять pip install, нужно будет заменить в requirements.txt tensorflow на tensorflow-macos. Этот код тестировался на Python 3.9.10.
Краткое описание каждого из файлов:
encoder.pyсодержит код BPE Tokenizer компании OpenAI, взятый напрямую из её репозитория gpt-2.utils.pyсодержит код для скачивания и загрузки весов модели GPT-2, токенизатора и гиперпараметров.gpt2.pyсодержит саму модель GPT и код генерации, которые можно запускать как скрипт на Python.gpt2_pico.py— это то же самое, что иgpt2.py, но с меньшим количеством строк. Зачем? А почему бы и нет.
Мы заново реализуем gpt2.py с нуля, так что удалим его и воссоздадим как пустой файл:
rm gpt2.py
touch gpt2.py
Для начала вставим в gpt2.py следующий код:
import numpy as np
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head):
pass # TODO: реализовать это
def generate(inputs, params, n_head, n_tokens_to_generate):
from tqdm import tqdm
for _ in tqdm(range(n_tokens_to_generate), "generating"): # цикл авторегрессивного декодирования
logits = gpt2(inputs, **params, n_head=n_head) # прямой проход модели
next_id = np.argmax(logits[-1]) # жадное сэмплирование
inputs = np.append(inputs, [next_id]) # добавляем прогноз к вводу
return list(inputs[len(inputs) - n_tokens_to_generate :]) # возвращаем только сгенерированные id
def main(prompt: str, n_tokens_to_generate: int = 40, model_size: str = "124M", models_dir: str = "models"):
from utils import load_encoder_hparams_and_params
# загружаем encoder, hparams, и params из опубликованных open-ai файлов gpt-2
encoder, hparams, params = load_encoder_hparams_and_params(model_size, models_dir)
# кодируем строку ввода при помощи BPE tokenizer
input_ids = encoder.encode(prompt)
# убеждаемся, что не вышли за пределы максимальной длины последовательности нашей модели
assert len(input_ids) + n_tokens_to_generate < hparams["n_ctx"]
# генерируем id вывода
output_ids = generate(input_ids, params, hparams["n_head"], n_tokens_to_generate)
# декодируем id обратно в строку
output_text = encoder.decode(output_ids)
return output_text
if __name__ == "__main__":
import fire
fire.Fire(main)Опишем каждую из четырёх частей:
- Функция
gpt2— это сам код GPT, который мы должны реализовать. Можно заметить, что наряду сinputsсигнатура функции содержит дополнительные параметры:wte,wpe,blocksиln_f— параметры модели.n_head— гиперпараметр, который нужно передавать во время прямого прохода.
- Функция
generate— это алгоритм авторегрессивного декодирования, который мы видели ранее. Для простоты мы пользуемся жадным сэмплированием.tqdm— это шкала прогресса, помогающая визуализировать процесс декодирования, один за другим генерирующего токены. - Функция
mainвыполняет следующие задачи:- Загружает токенизатор (
encoder), веса модели (params) и гиперпараметры (hparams) - Кодирует промпт ввода в ID токенов при помощи токенизатора
- Вызывает функцию generate
- Декодирует ID вывода в строку
- Загружает токенизатор (
fire.Fire(main)просто превращает наш файл в приложение CLI, чтобы мы могли запускать наш код следующим образом:python gpt2.py "здесь какой-то промпт"
Давайте присмотримся к encoder, hparams и params. Выполним в ноутбуке или интерактивной сессии Python следующее:
from utils import load_encoder_hparams_and_params
encoder, hparams, params = load_encoder_hparams_and_params("124M", "models")
При этом в models/124M скачаются необходимые файлы модели и токенизатора, а в наш код загрузятся encoder, hparams и params.
Encoder
encoder — это BPE tokenizer, используемый GPT-2:
>>> ids = encoder.encode("Not all heroes wear capes.")
>>> ids
[3673, 477, 10281, 5806, 1451, 274, 13]
>>> encoder.decode(ids)
"Not all heroes wear capes."
При помощи вокабулярия токенизатора (хранящегося в encoder.decoder) мы можем узнать, как выглядят реальные токены:
>>> [encoder.decoder[i] for i in ids]
['Not', 'Ġall', 'Ġheroes', 'Ġwear', 'Ġcap', 'es', '.']
Обратите внимание, что иногда токены — это слова (например, Not), иногда это слова, но с пробелом в начале (например, Ġall (Ġ обозначает пробел), иногда это часть слова (например, слово capes разделено на Ġcap и es), а иногда это знаки препинания (например, .).
BPE удобен тем, что может кодировать любую произвольную строку. Если он встречает то, чего нет в вокабулярии, то просто разбивает это на подстроки, которые понимает:
>>> [encoder.decoder[i] for i in encoder.encode("zjqfl")]
['z', 'j', 'q', 'fl']Также мы можем проверить размер вокабулярия:
>>> len(encoder.decoder)
50257
Вокабулярий, а также слияния байтовых пар, определяющие способ разбиения строк, получаются обучением токенизатора. Когда мы загружаем токенизатор, то загружаем уже обученный вокабулярий и слияния байтовых пар из каких-то файлов, которые были скачаны вместе с файлами модели, когда мы выполнили load_encoder_hparams_and_params. См. models/124M/encoder.json (вокабулярий) и models/124M/vocab.bpe (слияния байтовых пар).
Гиперпараметры
hparams — это словарь, содержащий гиперпараметры модели:
>>> hparams
{
"n_vocab": 50257, # количество токенов в вокабулярии
"n_ctx": 1024, # максимально возможная длина последовательности ввода
"n_embd": 768, # размерность эмбеддингов (определяет "ширину" сети)
"n_head": 12, # количество голов внимания (n_embd должно делиться на n_head)
"n_layer": 12 # количество слоёв (определяет "глубину" сети)
}
Мы будем использовать эти символы в комментариях к коду, чтобы показать внутреннюю структуру. Также мы будем использовать n_seq для обозначения длины последовательности ввода (например, n_seq = len(inputs)).
Параметры
params — это вложенный json-словарь, содержащий обученные веса модели. Узлы листьев json — это массивы NumPy. Если мы выведем params, заменив массивы на их shape, то получим следующее:
>>> import numpy as np
>>> def shape_tree(d):
>>> if isinstance(d, np.ndarray):
>>> return list(d.shape)
>>> elif isinstance(d, list):
>>> return [shape_tree(v) for v in d]
>>> elif isinstance(d, dict):
>>> return {k: shape_tree(v) for k, v in d.items()}
>>> else:
>>> ValueError("uh oh")
>>>
>>> print(shape_tree(params))
{
"wpe": [1024, 768],
"wte": [50257, 768],
"ln_f": {"b": [768], "g": [768]},
"blocks": [
{
"attn": {
"c_attn": {"b": [2304], "w": [768, 2304]},
"c_proj": {"b": [768], "w": [768, 768]},
},
"ln_1": {"b": [768], "g": [768]},
"ln_2": {"b": [768], "g": [768]},
"mlp": {
"c_fc": {"b": [3072], "w": [768, 3072]},
"c_proj": {"b": [768], "w": [3072, 768]},
},
},
... # повторяем для n_layers
]
}Всё это загружается из исходного чекпоинта tensorflow компании OpenAI:
>>> import tensorflow as tf
>>> tf_ckpt_path = tf.train.latest_checkpoint("models/124M")
>>> for name, _ in tf.train.list_variables(tf_ckpt_path):
>>> arr = tf.train.load_variable(tf_ckpt_path, name).squeeze()
>>> print(f"{name}: {arr.shape}")
model/h0/attn/c_attn/b: (2304,)
model/h0/attn/c_attn/w: (768, 2304)
model/h0/attn/c_proj/b: (768,)
model/h0/attn/c_proj/w: (768, 768)
model/h0/ln_1/b: (768,)
model/h0/ln_1/g: (768,)
model/h0/ln_2/b: (768,)
model/h0/ln_2/g: (768,)
model/h0/mlp/c_fc/b: (3072,)
model/h0/mlp/c_fc/w: (768, 3072)
model/h0/mlp/c_proj/b: (768,)
model/h0/mlp/c_proj/w: (3072, 768)
model/h1/attn/c_attn/b: (2304,)
model/h1/attn/c_attn/w: (768, 2304)
...
model/h9/mlp/c_proj/b: (768,)
model/h9/mlp/c_proj/w: (3072, 768)
model/ln_f/b: (768,)
model/ln_f/g: (768,)
model/wpe: (1024, 768)
model/wte: (50257, 768)
Показанный ниже код преобразует представленные выше переменные tensorflow в словарь params.
Для справки вот shape params, где числа заменены на hparams, которые они означают:
{
"wpe": [n_ctx, n_embd],
"wte": [n_vocab, n_embd],
"ln_f": {"b": [n_embd], "g": [n_embd]},
"blocks": [
{
"attn": {
"c_attn": {"b": [3*n_embd], "w": [n_embd, 3*n_embd]},
"c_proj": {"b": [n_embd], "w": [n_embd, n_embd]},
},
"ln_1": {"b": [n_embd], "g": [n_embd]},
"ln_2": {"b": [n_embd], "g": [n_embd]},
"mlp": {
"c_fc": {"b": [4*n_embd], "w": [n_embd, 4*n_embd]},
"c_proj": {"b": [n_embd], "w": [4*n_embd, n_embd]},
},
},
... # повторяем для n_layers
]
}Вероятно, вы захотите возвращаться к этому словарю, чтобы проверять shape весов в процессе реализации нашей GPT. Для согласованности имена переменных в нашем коде будут соответствовать ключам этого словаря.
Базовые слои
Прежде чем мы приступим к самой архитектуре GPT, давайте реализуем часть самых базовых слоёв сети, не специфичных конкретно для моделей GPT.
GELU
Для нелинейности (функция активации) выбора GPT-2 используется GELU (Gaussian Error Linear Units), альтернатива ReLU:

Рисунок 1 из научной статьи о GELU
Она аппроксимируется следующей функцией:
def gelu(x):
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))Как и ReLU, GELU обрабатывает ввод поэлементно:
>>> gelu(np.array([[1, 2], [-2, 0.5]]))
array([[ 0.84119, 1.9546 ],
[-0.0454 , 0.34571]])Использование GELU в моделях-трансформерах популяризировала BERT, и я думаю, её продолжат применять ещё долго.
Softmax
Старый добрый softmax:

def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
Для числовой стабильности мы используем трюк с max(x).
Softmax применяется для преобразования множества вещественных чисел (от  до
до  ) в вероятности (от 0 до 1, где сумма всех чисел равна 1). Мы применяем
) в вероятности (от 0 до 1, где сумма всех чисел равна 1). Мы применяем softmax для последней оси ввода.
>>> x = softmax(np.array([[2, 100], [-5, 0]]))
>>> x
array([[0.00034, 0.99966],
[0.26894, 0.73106]])
>>> x.sum(axis=-1)
array([1., 1.])Нормализация слоёв
Нормализация слоёв стандартизирует значения так, чтобы они имели среднее значение 0 и дисперсию 1:

где  — среднее
— среднее  ,
,  — дисперсия
— дисперсия  , а
, а  и
и  — изучаемые параметры.
— изучаемые параметры.
def layer_norm(x, g, b, eps: float = 1e-5):
mean = np.mean(x, axis=-1, keepdims=True)
variance = np.var(x, axis=-1, keepdims=True)
x = (x - mean) / np.sqrt(variance + eps) # нормализуем x, чтобы иметь mean=0 и var=1 по последней оси
return g * x + b # масштабируем и смещаем с параметрами gamma/betaНормализация слоёв гарантирует, что вводы для каждого слоя будут находиться в согласованном интервале, что должно ускорить и стабилизировать процесс обучения. Как и при Batch Normalization, нормализированный вывод затем масштабируется и смещается при помощи двух изучаемых векторов gamma и beta. Небольшой член epsilon в делителе используется, чтобы избежать ошибку деления на ноль.
По разным причинам в трансформере используется не batch norm, а норма слоёв. Различия между разными методиками нормализации описаны в этом замечательном посте.
Мы применяем нормализацию слоёв для последней оси ввода.
>>> x = np.array([[2, 2, 3], [-5, 0, 1]])
>>> x = layer_norm(x, g=np.ones(x.shape[-1]), b=np.zeros(x.shape[-1]))
>>> x
array([[-0.70709, -0.70709, 1.41418],
[-1.397 , 0.508 , 0.889 ]])
>>> x.var(axis=-1)
array([0.99996, 1. ]) # учитываем тонкости работы с плавающей запятой
>>> x.mean(axis=-1)
array([-0., -0.])Линейность
Стандартное матричное умножение + перекос:
def linear(x, w, b): # [m, in], [in, out], [out] -> [m, out]
return x @ w + bЛинейные слои часто называют проекциями (поскольку они проецируют из одного векторного пространства в другое).
>>> x = np.random.normal(size=(64, 784)) # input dim = 784, batch/sequence dim = 64
>>> w = np.random.normal(size=(784, 10)) # output dim = 10
>>> b = np.random.normal(size=(10,))
>>> x.shape # shape до линейного проецирования
(64, 784)
>>> linear(x, w, b).shape # shape после линейного проецирования
(64, 10)Продолжение следует.
Автор:
PatientZero







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}